基础章节-01-MySQL数据库服务中级课程#

1.00 课程知识章节说明#
目前在互联网的实际应用中,各个企业都会比较关注自身网站的数据信息,既要保证数据信息的安全性,同时也要保证数据存储读取效率
并且在特殊的场景下,还要对存储的数据信息进行检索和分析;因此数据库服务业务已经在各行各业应用非常的广泛
对于互联网领域的技术人员,对于数据库服务知识的掌握,也将是在求职时必备的技能,有些时候还会绝对入职的定级和薪资水平。
1.19 数据库服务分区应用#
1.19.1 数据库服务分区概述#
MySQL从5.1版本开始支持分区的功能;分区是指根据一定的规则,数据库把一个大表分解成多个更小的、更容易管理的部分;
通俗说明:表分区就是将一个大表,根据条件分割成若干个小表;
日常项目开发中经常会遇到大表的情况,所谓大表是指存储了百万级乃至千万级条记录的表。
这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下;如果涉及联合查询情况,性能会更加糟糕;
对表进行分区,目的就是减少数据库的负担,提高数据库的效率,通常来讲就是提高表的增删改查效率
分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器;
分区后,表面上还是一张表,但数据散列到多个位置了;
应用程序读写的时候操作的还是大表名字,数据库系统自动去组织分区的数据
就访问数据库的应用而言,逻辑上只有一个表或一个索引,但是实际上这个表可能由数10个物理分区对象组成;
每个分区都是一个独立的对象,可以独自处理,可以作为表的一部分进行处理
分区对应用来说是完全透明的,不影响应用的业务逻辑
例如:某个用户表的记录超过了600万条会员信息,那么就可以根据入会日期将表分区,也可以根据所在地将表分区;
当然也可以根据其他的条件分区;
为了改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率,因此具有了对表分区的需求;
MySQL分区的优点主要包括以下4个方面:
和单个磁盘或者文件系统分区相比,可以存储更多数据;(ext2分区单个文件2T ext3 ext4分区单个文件16T)
优化查询,在where子句中包含分区条件时,可以只扫描必要的一个或多个分区来提高查询效率;
使一些查询操作可以得到极大的优化;
对于已经过期或者不需要保存的数据,可以通过删除与这些数据有关的分区来快速删除数据;
通过删除与增加那些数据有关的分区,很容易地删除或增加那些数据;
通过跨多个磁盘甚至服务器来分散数据查询,以获得更大的查询吞吐量;
在MySQL5.5之后支持所有函数的分区优化,限定只查询有效数据的分区
同时在涉及SUM()和COUNT()这类聚合函数的查询时,可以容易地在每个分区上并行处理,最终只需要汇总所有分区得到的结果
1
| select count(*) from employees where gender='F';
|
1.19.2 数据库服务分区技术#
分区有利于管理非常大的表,它采用了"分而治之"的逻辑,分区引入了分区键(partition-key)的概念;
分区键用于根据某个区间值(或者范围值)、特定值列表或者HASH函数值执行数据的聚集,让数据根据规则分布在不同的分区中;
最终让一个大对象变成一些小对象。
1.19.3 数据库服务分区类型(mycat 分布式存储策略–分表策略) ***#
对于MySQL基本常用的分区类型有:基本分区类型
RANGE分区:
基于属于一个给定连续区间的列值,把多行分配给分区;
LIST分区:
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择;
HASH分区:
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算;
这个函数可以包含MySQL中有效的,产生非负整数值的任何表达式
KEY分区:
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值
实战演示分区操作:RANGE分区
基于属于一个给定连续区间的列值,把多行分配给分区;
这些区间要连续且不能相互重叠,使用values less than操作符来进行定义
创建分区操作:在创建表的过程中也可以直接创建分区
例如:将用户表按照年龄每个10岁进行分区;
注意:分区的名字基本上遵循其他MySQL标识符应当遵循的原则,但是分区的名字是不区分大小写的;
1
2
3
4
5
6
7
8
| create table t1 (id int,name varchar(20),age int)
partition by range (age)
(
partition p01 values less than (10),
partition p02 values less than (20),
partition p03 values less than (30),
partition p04 values less than (maxvalue)
);
|
在数据表进行分区操作后,会发现表的空间文件发生了拆分变化;
1
2
3
4
5
6
7
| [root@db-01 xiaoQ]# pwd
/data/3306/data/xiaoQ
[root@db-01 xiaoQ]# ll
-rw-r----- 1 mysql mysql 114688 Jul 18 09:33 t1#p#p01.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 09:33 t1#p#p02.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 09:33 t1#p#p03.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 09:33 t1#p#p04.ibd
|
修改分区操作:在已有表的基础上也可以直接设置分区
例如:根据表中的年份列进行分区存储数据;
1
2
3
4
5
6
7
8
9
10
| alter table t2
partition by range (year(from_date))
(
partition p01 values less than (1985),
partition p02 values less than (1986),
partition p03 values less than (1987),
partition p04 values less than (1988),
partition p15 values less than (1999),
partition p16 values less than (MAXVALUE)
);
|
实战演示分区操作:LIST分区
类似于按RANGES分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值进行选择;
LIST分区通过使用" partition by list(expr) “来实现,其中” expr “是某列值或一个基于某个列值、并返回一个整数值的表达式;
然后通过” values in (value_list) “的方式来定义每个分区,其中” value_list “是一个通过逗号分隔的整数列表;
在MySQL 5.1中,当使用LIST分区时,默认只能匹配整数列表,这个问题在MySQL5.5版本中得到了解决。
columns 关键字现在允许字符串和日期列作为分区定义列。对应的语法例子会在多列分区中提到;
对于一个综合性的网店来说,商品分为诸多种类;可以按照商品类别ID进行range分区,也可以按照商品的类型划分分区;
在这个例子中,List分区给了我们更多的选择
创建分区操作:在创建表的过程中也可以直接创建分区
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by list(cid)
(
partition p01 values in (1,2,3),
partition p02 values in (4,5,6),
partition p03 values in (7,8,9)
);
修改大表信息转变为list分区表:
alter table t2
partition by list(cid)
(
partition p01 values in (1,2,3),
partition p02 values in (4,5,6),
partition p03 values in (7,8,9)
);
|
实战演示分区操作:HASH分区
基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算;
这个函数可以包含MySQL中有效的、产生非负整数值的任何表达式;
要使用HASH分区来分割一个表,要在create table语句上添加一个"partition by hash(expr)“子句,
其中"expr"是一个返回整数的表达式,可以仅仅是字段类型为MySQL整型的一列的名字;
此外,很可能需要在后面再添加一个"partitions num"子句,其中num是一个非负的整数,表示表将要被分割成分区的数量;
如果没有书写上"partitions num"子句,那么分区的数量将默认为1;
使用HASH分区的有点在于数据分布较为均匀;
创建分区操作:在创建表的过程中也可以直接创建分区
在MySQL Cluster中,分区行为是自动的,默认情况下,分区的数量和ndb node数量相同;
通常在节点数很多的情况下,会通过配置分区数和node group搭配进行调整;
1
2
3
| create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by hash(cid)
partitions 4;
|
实战演示分区操作:LINEAR HASH分区
线性与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则;
而常规哈希使用的是求哈希函数值的模数;
按照线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量(1T)数据的表;
不过,MySQL的线性哈希算法导致相比常规哈希,数据可能分布的不那么均衡,容易产生"hotspot nodes”
关于LINEAR HASH算法参加MySQL官方文档:
https://dev.mysql.com/doc/refman/5.7/en/partitioning-linear-hash.html
线性哈希分区和常规哈希分区在语法上的唯一区别在于,在"partition by"子句中添加了"LINEAR"关键字:
1
2
3
| create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by linear hash(cid)
partitions 4;
|
实战演示分区操作:KEY分区(了解即可)
按照key进行分区类似于按照hash分区,除了hash分区使用的用户定义的表达式,而key分区的哈希函数是由MySQL服务器提供;
MySQL簇(cluster)使用函数MD5()来实现key分区;
对于使用其他存储引擎的表,服务器使用其自身内部的哈希函数,这些函数是基于与PASSWORD()一样的运算法则;
1
2
3
4
5
6
| create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by key(cid)
partitions 4;
create table t2 (id int,cid int,name varchar(20),pos_date datetime)
partition by linear key(cid)
partitions 4;
|
实战演示分区操作:多列分区
columns关键字允许字符串和日期列作为分区定义列,同时还允许使用多个列定义一个分区;
1
2
3
4
5
6
7
8
9
| create table t3 (a int,b int,c int)
partition by range columns(a,b)
(
partition p01 values less than (10,10),
partition p02 values less than (10,20),
partition p03 values less than (10,30),
partition p04 values less than (10,maxvalue),
partition p05 values less than (maxvalue,maxvalue)
);
|
第一个分区用来存储雇佣与1990年以前的女职员;
第二个分区存储用于1990-2000年之前的女职员;
第三个分区存储所有剩余的女职员;
对于分区p04到p06,使用的分区策略是一样的,只不过存储的是男职员,最后一个分区是控制情况;
1
2
3
4
5
6
7
8
9
10
11
| create table employees (emp_no int,birth_date date,first_name varchar(20),last_name varchar(20),gender char(1),hire_date date) engine=Innodb
partition by range columns(gender,hire_date)
(
partition p01 values less than ('F','1990-01-01'),
partition p02 values less than ('F','2000-01-01'),
partition p03 values less than ('F',maxvalue),
partition p04 values less than ('M','1990-01-01'),
partition p05 values less than ('M','2000-01-01'),
partition p06 values less than ('M',maxvalue),
partition p07 values less than (maxvalue,maxvalue)
);
|
1.19.4 数据库服务特殊分区#
在MySQL中还有一种特殊的分区方式称为子分区;
子分区是分区表中每个分区的再次分割;
子分区可以用于特别大的表,在多个磁盘间分配数据和索引
1
2
3
4
5
6
7
8
9
| create table t5 (id int, updateinfo date)
partition by range(year(updateinfo))
subpartition by hash ( to_days(updateinfo))
subpartitions 2
(
partitions p0 values less than (1990),
partitions p1 values less than (2000),
partitions p2 values less than maxvalue
);
|
可以查看表数据文件信息,可以到子分区后的数据文件的拆分情况;
1
2
3
4
5
6
7
| [root@db-01 xiaoQ]# ll /data/3306/data/xiaoQ/
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p0#sp#p0sp0.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p0#sp#p0sp1.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p1#sp#p1sp0.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p1#sp#p1sp1.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p2#sp#p2sp0.ibd
-rw-r----- 1 mysql mysql 114688 Jul 18 11:55 t5#p#p2#sp#p2sp1.ibd
|
实战演示分区操作:子分区
将每个子分区保存在不同的存储上,优化I/O性能;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
| create table ts (id int, updateinfo date)
partition by range(YEAR(updateinof ))
subpartition by hash(to_days(updateinfo))
(
partition p0 values less than (1990)
)
subpartition s0
data directory = '/disk0/data'
index directory = '/disk0/idx',
subpartition s1
data directory = '/disk1/data'
index directory = '/disk1/idx',
);
# 实战操作演示:
[root@db-01 var]# cd /var
[root@db-01 var]# mkdir {a..d}/{data,idx} -p
[root@db-01 var]# chown -R mysql. {a..d}
-- 准备好相应的存储目录
[root@db-01 var]# cat /etc/my.cnf
[mysqld]
innodb_directories="/var/a/data;/var/a/idx;/var/b/data;/var/b/idx;/var/c/data;/var/c/idx;/var/d/data;/var/d/idx"
-- 在innodb存储引擎中,需要设置innodb_directories的信任目录信息,才能将子分区文件保存在不同的存储上
-- 官方资料参考:https://dev.mysql.com/doc/refman/8.0/en/innodb-create-table-external.html
# 基于MyISAM存储引擎操作时;
create table t6 (id int, updateinfo date)
partition by range(YEAR(updateinfo))
subpartition by hash(to_days(updateinfo))
(
partition p01 values less than (1990)
(
subpartition s0
data directory='/var/a/data'
index directory='/var/a/idx',
subpartition s1
data directory='/var/b/data'
index directory='/var/b/idx'
),
partition p02 values less than (2000)
(
subpartition s2
data directory='/var/c/data'
index directory='/var/c/idx',
subpartition s3
data directory='/var/d/data'
index directory='/var/d/idx'
)
);
# 基于Innodb存储引擎操作时;
create table t6 (id int, updateinfo date)
partition by range(YEAR(updateinfo))
subpartition by hash(to_days(updateinfo))
(
partition p01 values less than (1990)
(
subpartition s0
data directory='/var/a/data',
subpartition s1
data directory='/var/b/data'
),
partition p02 values less than (2000)
(
subpartition s2
data directory='/var/c/data',
subpartition s3
data directory='/var/d/data'
)
);
# 子分区后的表文件信息查看
[root@db-01 var]# ll /var/{a..d}/data/oldboy
/var/a/data/oldboy:
总用量 112
-rw-r----- 1 mysql mysql 114688 9月 29 02:58 t6#p#p01#sp#s0.ibd
/var/b/data/oldboy:
总用量 112
-rw-r----- 1 mysql mysql 114688 9月 29 02:58 t6#p#p01#sp#s1.ibd
/var/c/data/oldboy:
总用量 112
-rw-r----- 1 mysql mysql 114688 9月 29 02:58 t6#p#p02#sp#s2.ibd
/var/d/data/oldboy:
总用量 112
-rw-r----- 1 mysql mysql 114688 9月 29 02:58 t6#p#p02#sp#s3.ibd
|
子分区语法要求:
每个子分区必须有相同数量的子分区;
如果在一个分区表上的任何分区使用subpartition来明确定义任何子分区,那么就必须定义所有的子分区;
若不按照上面说法操作,就会出现以下语句信息的执行报错:
1
2
3
4
5
6
7
8
9
10
11
12
| create table t7 (id int, updateinfo date)
partition by range(YEAR(updateinfo))
subpartition by hash(to_days(updateinfo))
(
partition p01 values less than (1990)
(subpartition s0,subpartition s1),
partition p02 values less than (2000)
(subpartition s2,subpartition s3),
partition p03 values less than (maxvalue)
);
ERROR 1064 (42000): Wrong number of subpartitions defined, mismatch with previous setting near '
)' at line 9
|
1.19.5 数据库服务分区管理#
不同分区管理也是有所不同的~
简单修改分区:
下面这个例子使用alter语句简单修改分区,效果和先删除原表在按新的分区方式重新建表效果相同;
按照使用id列值作为键的基础,通过key分区把它重新分成两个分区;
1
| alter table t3 partition by key(id) partitions 2;
|
利用上面的分区表修改命令,可以将没有分区过的表进行分区,同时也可以将已经分区的表进行修改分区信息;
删除指定分区:(range和List分区)
删除指定的range或list分区非常简单,但是要注意删除分区也同时删除了该分区中所有的数据;
如果仅仅想删除分区表中的数据,应该使用truncate语句;
1
2
3
4
| alter table t1 drop partition p02;
-- 进行表分区删除
alter table t1 truncate partition p01;
-- 进行表分区数据删除,但表分区还在
|
添加新的分区:
range分区中添加分区
要添加一个新的range或list分区到一个前面已经分区的表,使用alter table … add partition语句;
对于使用range分区的表,可以用这个语句添加新的区间到已有分区的序列前面或后面
对于range分区的表,只可以使用add partition添加新的分区到分区列表的高端;
以下是一个错误添加分区的例子:
1
2
3
4
5
6
7
| ...
partition by range(YEAR(dob))(
partition p0 values less than (1970),
partition p1 values less than (1980)
)
alter table t1 add partition (partition p2 values less than (1960));
ERROR 1493 (HY000): VALUES LESS THAN value must be strictly increasing for each partition
|
List分区中添加分区
对List分区增加分区的语法和range类似;
增加新分区时,不可以包含现有分区值列表中的任意值
以下是一个错误添加分区的例子:
1
2
3
4
5
6
| ...
partition by list(data)(
partition p0 values in (5,10,15),
partition p1 values in (6,12,18),
)
alter table t2 add partition (partition p2 values in (4,8,12));
|
分区重组操作:
使用reorganize可以对现有的分区进行重组,
这样可以实现将一个已存在的分区重分成多个分区,也可以实现将多个分区合并成一个分区
新分区模式不能有任何重叠的区间(适用于按照range分区的表)或值集合(适用于重新组织按照list分区的表),也必须覆盖原有区间
对于按照range分区的表,只能重新组织相邻的分区,不能跳过range分区;
1
2
3
4
5
6
7
| alter table t1 reorganize partition p01 into (
partition s0 values less than (5),
partition s1 values less than (10))
-- 表示将p01原有一个分区拆分为s0,s1两个分区
alter table t1 reorganize partition s0,s1 into (
partition p01 values less than (10))
-- 表示将s0,s1原有两个分区合并为p01一个分区
|
1.20 数据库服务全面优化#
1.19.1 数据库服务硬件层面优化#
硬件配置建议:
| 选型建议 | 具体选择说明 |
|---|
| 存储设备厂商 | DELL、HP、IBM、华为、浪潮 |
| CPU选型 | Inter-I系列、E系列(Xeon) |
| 内存选型 | 具有ECC功能特性内存(Error Correcting Code 错误检查和纠正技术),提高计算机运行的稳定性和增加可靠性 |
| IO存储选型 | SAS、pci-e SSD、Nvme flash |
| Raid选型 | Raid 10 |
| 网卡选型 | 单卡单口网卡(使用寿命较长) |
| 云存储选型 | ECS、RDS、PolarDB、TDSQL |
硬件参数调配
关闭numa功能,从而提高数据库服务应用性能(提高QPS效率)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| # 关闭Numa(早期SMP)
# 关闭方式一:bios级别关闭
参见下图关闭(实现让mysql多使用一些内存空间)
numactl --hardware
available:1 node(0) -- 如果是2或多个nodes就说明numa没关闭
-- 在bios层面numa关闭时,无论os层面的numa是否关闭,都不会影响数据库服务性能;
# 关闭方式二:os grub级别关闭
[root@xiaoQ ~]# vim /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="spectre_v2=retpoline net.ifnames=0 rhgb quiet numa=off "
GRUB_DISABLE_RECOVERY="true"
[root@xiaoQ ~]# grub2-mkconfig -o /etc/grub2.cfg
-- 重新生成/etc/grub2.cfg配置文件
[root@xiaoQ ~]# reboot
[root@master grub2]# dmesg|grep -i numa
[ 0.000000] NUMA turned off
-- 重启系统后确认numa是否关闭
[root@master grub2]# cat /proc/cmdline
BOOT_IMAGE=/vmlinuz-3.10.0-1160.el7.x86_64 root=UUID=f2d5232b-945e-4e7a-b76f-7ec609c35499 ro spectre_v2=retpoline net.ifnames=0 rhgb quiet
LANG=en_US.UTF-8 numa=off
-- 再次核实确认
-- 在OS层numa关闭时,打开bios层的numa会影响性能,QPS会下降15~30%;
# 关闭方式三:数据库级别关闭
mysql> show variables like '%numa%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| innodb_numa_interleave | OFF |
+------------------------+-------+
1 row in set (0.04 sec)
或者
[root@xiaoQ ~]# vim /etc/init.d/mysqld
# Give extra arguments to mysqld with the my.cnf file. This script
# may be overwritten at next upgrade.
$bindir/mysqld_safe --datadir="$datadir" --pid-file="$mysqld_pid_file_path" $other_args >/dev/null &
wait_for_pid created "$!" "$mysqld_pid_file_path"; return_value=$?
-- 将$bindir/mysqld_safe --datadir="$datadir"这一行修改为:
/usr/bin/numactl --interleave all $bindir/mysqld_safe --datadir="$datadir" --pid-file="$mysqld_pid_file_path" $other_args >/dev/null &
wait_for_pid created "$!" "$mysqld_pid_file_path"; return_value=$?
|
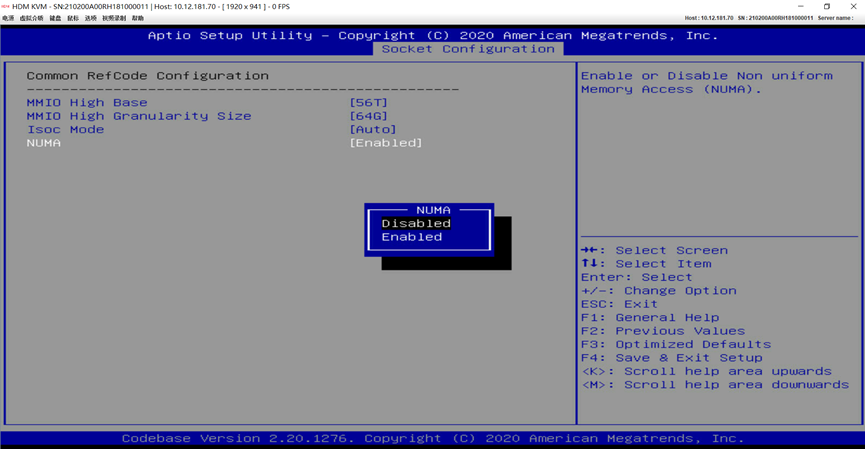
开启CPU高性能模式:
阵列卡配置建议:
推荐选择raid10阵列级别,存储设备选择SSD或者PCI-E或者Flash;
如果有可能需要开启cache功能,需要配合UPS、多路电源、发电机使用;
设置强制回写(Force writeBack),表示先将数据写入到raid卡缓冲区,再将缓冲区数据写入到对应磁盘中;
利用BBU电池,没电会有较大性能影响,需要定期充放电,如果有UPS、并且采用多路电源、配合发电机,BBU功能可关闭
需要关闭阵列卡预读功能,即在读取某个数据信息时,也会把其它的相关数据读入到缓存中;
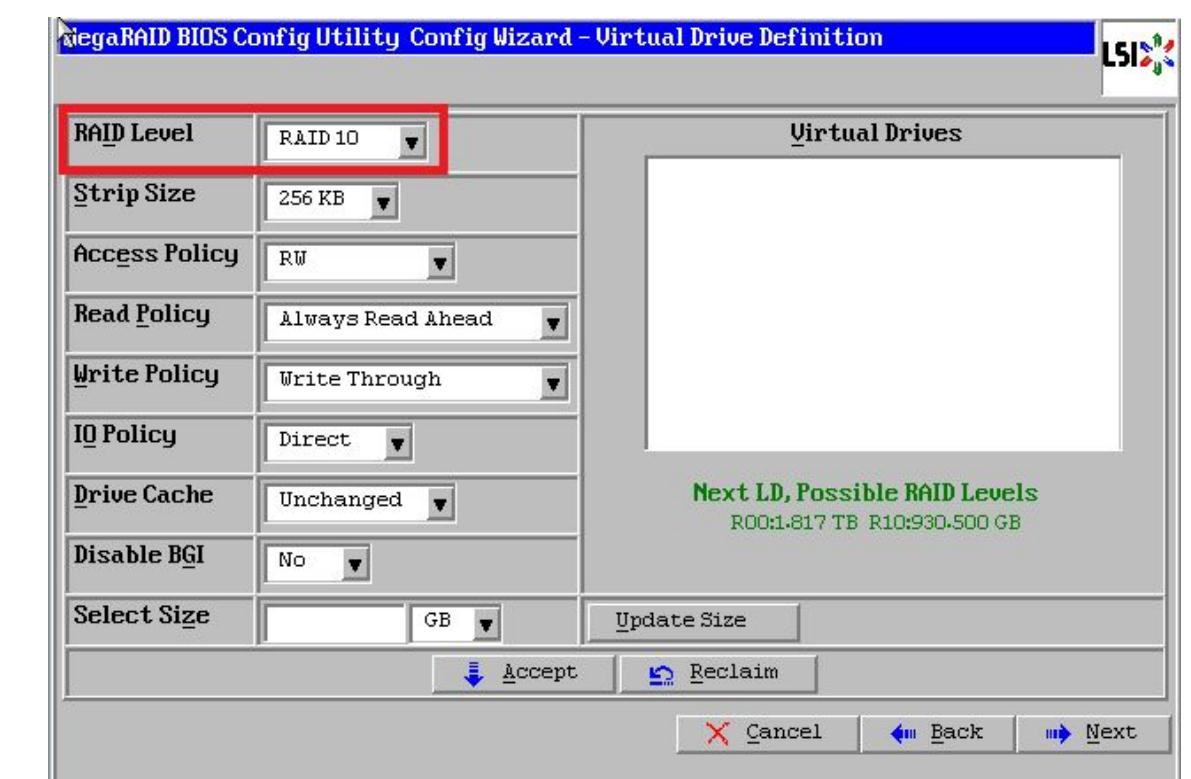
关闭THP(Transparent Huge Pages 透明大页内存)
默认使用内存页大小为4KB,正好对应数据库存储的数据页16k(4个内存页),但是当应用大页内存时,单位内存页存储大小变为2M;
MySQL 5.0.3之后在linux上支持huge page,可以使用 large-page 选项启动MySQL;
在数据库服务引用大页内存后,至少可以有两个明显的好处:
可以减少 Translation Lookaside Buffer (TLB) 失误以提高性能;
TLB主要用于缓存页表信息,实现提高虚拟内存地址到物理内存地址的转换速度
利用huge page避免应用swap的特性,保证MySQL的内存不会被交换到swap中;
以上是说明大页内存的好处,但是若使用大页内存,意味着数据库中的数据页是16K,放在一个大页内存中很容易产生内存碎片;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| # 系统内存信息查看
[root@xiaoQ ~]# getconf PAGE_SIZE
4096
-- 默认内存页大小
[root@xiaoQ ~]# grep Huge /proc/meminfo
HugePages_Total: 0
HugePages_Free: 0
Hugepagesize: 2048 kB
-- 默认系统没有分配大页内存
# 禁用大页内存功能
# 临时关闭
[root@xiaoQ ~]# vim /etc/rc.local
[root@xiaoQ ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
-- always 表示一直都在未关闭
[root@xiaoQ ~]# echo never >/sys/kernel/mm/transparent_hugepage/enabled
[root@xiaoQ ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
-- never 表示大页内存功能已关闭
# 永久关闭
[root@xiaoQ ~]# vi /etc/rc.local
-- 在文件末尾添加如下指令:
-- 先判断是否存在这个文件,再进行修改
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then
echo never > /sys/kernel/mm/transparent_hugepage/enabled
fi
if test -f /sys/kernel/mm/transparent_hugepage/defrag; then
echo never > /sys/kernel/mm/transparent_hugepage/defrag
fi
[root@xiaoQ ~]# cat /sys/kernel/mm/transparent_hugepage/enabled
always madvise [never]
[root@xiaoQ ~]# cat /sys/kernel/mm/transparent_hugepage/defrag
always madvise [never]
-- 进行脚本执行完毕后检查确认
|
网卡绑定操作:
利用bonding技术实现业务数据库服务器的网卡绑定,建议网卡绑定模式设置为主备,不同网卡连接多个交换机,需要设置交换机堆叠;
Linux绑定技术-bonding、HP unix-APA、IBM unix-EtherChannal
存储多路径配置:(有外置存储设备时)
使用独立存储设备时,需要配置多路径功能,Linux自带多路径配置为 multipath(多路径聚合),对应存储设备产生也有多路径配置
存储使用多路径配置作用:
- 实现冗余,为了保证存储访问的可靠性
一般至少需要用2块光纤卡,通过2个FC switch接在磁盘阵列的两个控制器上,当一条路径出现问题,还有另一条路径可以访问.
- 实现负载均衡.
若有2个path,如果某一个path只是备用就浪费了,所以MultiPathing的软件的另一个功能就是load balance).
但这个功能不仅仅由MultiPathing软件实现,磁盘阵列本身也必需支持,否则,MultiPathing只能实现主备方式
1.19.2 数据库服务系统层面优化#
更改文件句柄和进程数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| [root@xiaoQ ~]# vim /etc/sysctl.conf
vm.swappiness = 5
-- 也可以设置为0 (/proc/sys/vm/swappiness) 物理内存剩余的百分比之后,使用swap
-- 参数值越大,越积极使用swap空间,参数值越小,越积极使用物理内存
-- 默认值为可以通过cat /proc/sys/vm/swappiness命令查看
vm.dirty_ratio = 20
-- 表示可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,
-- 同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。
-- 这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.dirty_background_ratio = 10
-- 定义内存中脏页的刷新比例,在指定比例之上就要刷写脏页
net.ipv4.tcp_max_syn_backlog = 819200
net.core.netdev_max_backlog = 400000
net.core.somaxconn = 4096
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 0
[root@xiaoQ ~]# vim /etc/security/limits.conf
hard nofile 63000
-- 可打开的文件描述符的最大数(超过会报错);
soft nofile 63000
-- 可打开的文件描述符的最大数(超过会警告);
lsof |wc -l
-- 查看所有进程打开的文件数信息
/usr/sbin/lsof -p 27419 |wc -l
-- 查看某个进程打开的文件数信息
|
防火墙与selinux安全设置:
1
2
3
4
5
6
7
8
| [root@xiaoQ-01 ~]# systemctl is-active firewalld
unknown
[root@xiaoQ-01 ~]# systemctl is-enabled firewalld
disabled
-- 查看防火墙服务是否关闭,如果有需要开启时,别忘把数据库服务相关的端口开启即可
[root@xiaoQ-01 ~]# getenforce
Disabled
-- 查看selinux安全策略是否关闭
|
文件系统优化设置
1
2
3
4
5
| # 推荐使用XFS文件系统,并设置数据库的数据为独立分区,不建议使用LVM
挂载点为: /data
挂载参数:defaults,noatime,nodiratime,nobarrier
[root@xiaoQ-01 ~]# vim /etc/fstab
/dev/sdb1 /data xfs defaults,noatime,nodiratime,nobarrier 1 2
|
io调度设置
在系统中的io调度器的总体目标是:希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型;
所以IO调度器也被叫做电梯. (elevator)而相应的算法也就被叫做电梯算法.
而Linux中IO调度的电梯算法有好几种:
as (Anticipatory)
已经废弃–
cfq (Complete Fairness Queueing-完全公平排队I/O调度程序)
为每个进程/线程,单独创建一个队列来管理该进程所产生的请求,也就是说每个进程一个队列,各队列之间的调度使用时间片来调度,
以此来保证每个进程都能被很好的分配到I/O带宽,I/O调度器每次执行一个进程的4次请求.
deadline
确保了在截止时间内完成服务请求,这个截止时间是可调整的,默认读期限短于写期限;
Deadline对数据库环境(ORACLE RAC,MYSQL等)是最好的选择.
noop(No Operation-电梯式调度程序)
该算法实现了最简单的FIFO队列,所有I/O请求大致按照先来后到的顺序进行操作。
实现了一个简单的FIFO队列,就像电梯的工作方法一样对I/O请求进行组织。
具体使用哪种算法我们可以在启动的时候通过内核参数elevator来指定.
1
2
3
4
5
| #SAS deadline/SSD&PCI-E: noop
[root@xiaoQ-01 ~]# echo deadline > /sys/block/sda/queue/scheduler
或者
[root@xiaoQ ~]# vim /etc/default/grub
GRUB_CMDLINE_LINUX="spectre_v2=retpoline net.ifnames=0 elevator=deadline rhgb quiet"
|
1.19.3 数据库服务软件版本选择#
建议选择开源社区版本,并且选择稳定的GA版本;
选择数据库服务GA版本时,最好是发布了6个月12个月的GA双数版本,大约在1520个小版本左右;
选择数据库服务版本时,要主要选择前后几个月没有大的BUG修复的版本,而不是大量修复BUG的集中版本;
选数据库服务版本还要考虑开发人员所开发程序使用的版本是否与实际数据库应用兼容;
选择好数据库服务版本后,建议内部开发人员测试下数据库环境,跑大概3~6个月的时间;
企业非核心业务可以优先采用新版本的数据库进行应用;
可以多咨询DBA大佬,或者在技术氛围好的群里进行交流咨询,使用真正的高手们用过且好用的GA版本产品;
说明:最终建议可以选择8.0.20,以及8.0.20之后的双数版本;
1.19.4 数据库服务结构参数优化#
01 数据库连接层优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| # 连接层相关优化参数
max_connections=1000
-- 单节点建议不高于3000
max_connect_errors=999999
-- 定义最大连接失败的次数,当超过定义的数值,就会影响正常的连接建立
wait_timeout=600
-- 定义连接会话的超时时间(释放更多的连接数),具体指定sleep连接会话的超时时间
interactive_timeout=3600
-- 定义连接会话的超时时间(释放更多的连接数),定义交互式的超时时间
net_read_timeout=120
net_write_timeout=120
-- 定义网络传输读或写数据包的超时时间;
max_allowed_packet=32M
-- 定义允许的最大数据包大小
|
02 数据库服务层优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| # 服务层相关优化参数
sql_safe_updates = 1
-- 设置当使用update或delete命令时,必须加上where才能执行
slow_query_log = ON
slow_query_log_file = /xxx
long_query_time = 1
log_queries_not_using_indexes = ON
log_throttle_queries_not_using_indexes = 10 -- 不走索引的相同索引语句只记录指定的次数
-- 进行数据库慢日志信息相关配置
sort_buffer_size = 262144
join_buffer_size = 262144
read_buffer_size = 131072
read_rnd_buffer_size = 262144
-- 定义session级别的缓冲区大小,不建议设置大小超过8M,因为是根据每个会话进行的缓冲区分配;
tmp_table_size = 16777216
max_heap_table_size = 16777216
-- 生成的临时表空间建议不超过128M
max_execution_time = 28800
-- 当跑大的事务操作时,可以设置事务最大的执行时间,建议再跑批量操作时,可以设置大些
lock_wait_timeout = 60
-- 表示设置锁等待的时间,当锁定时间到达指定时间后,会实现自动解锁(主要针对元数据锁,默认是1年)
lower_case_table_names = 1
-- 表示创建表时,自动将表名的大写信息转化为小写;(必须初始化时进行设置)
thread_cache_size = 64
-- 表示设置线程缓存的个数信息,可以使线程缓存资源进行复用,从而减少CPU工作压力;(比如连接线程就可以应用)
character_set_server = utf8mb4
-- 设置数据库服务端字符集,建议设置为utf8或utf8mb4
log_timestamps = SYSTEM
-- 表示设置日志信息的时间尽量和系统时间信息保持一致
init_connect = '普通用户登录信息'
init_connect='insert into auditdb.access(thread_id,login_time,localname,matchname) values (connection_id(),now(),user(),current_user());'
-- 一般在进行审计时进行使用,表示普通用户登录时,自动进行相应语句的操作
-- 参考链接说明:https://blog.csdn.net/mingli_a/article/details/115351986
event_scheduler = OFF
-- 事件调度信息一般不用使用,关闭即可
secure-file-priv=/tmp
-- 当需要在数据库子系统中把信息导出到当前系统指定目录文件中时,进行使用
expire_logs_days = 10
sync_binlog = 1
log_bin = ON
log_bin_basename = /data/3306/binlog/mysql-bin
log_bin_index = /data/3306/binlog/mysql-bin.index
max_binlog_size = 500M
binlog_format = ROW
max_binlog_cache_size = 2G
max_binlog_stmt_cache_size = 2G
-- 表示和binlog有关的配置信息
|
03 数据库引擎层优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| # 引擎层相关优化参数
transaction_isolation = "READ-COMMITTED"
-- 设置事务默认隔离级别,基本RC级别即可
innodb_data_home_dir = /xxx
-- 表示定义共享表空间文件ibdate存储路径(了解即可)
innodb_log_group_home_dir = /xxx
-- 表示定义redo日志文件存储路径(了解即可)
innodb_log_file_size = 2048M
-- 表示定义redo日志单个文件大小(建议1~4G)
innodb_log_files_in_group = 3
-- 表示定义redo日志文件的组数(一般可以定义为3~4组)
innodb_flush_log_at_trx_commit = 2
-- 表示定义事务redo日志刷新到磁盘的策略(双一配置中的其中一个),有binlog日志时,可以不用设置为1
innodb_flush_method = O_DIRECT
-- 表示log buffer中的信息是直接写入到磁盘中的,而不经过系统的buffer(建议硬盘配合SSD使用)
innodb_io_capacity = 1000
innodb_io_capacity_max = 4000
-- 表示每次IO可以刷新数据页的数量(SSD盘按照以上配置 SAS盘按照默认即可)
innodb_buffer_pool_size = 64G
-- 表示定义buffer pool的空间大小(基于128G内存配置,建议不要超过75~80%)
innodb_buffer_pool_instances = 4
-- 表示将定义好的buffer pool空间可以拆分为4份,给不同的实例进行使用,避免相同内存空间的争用;
innodb_log_buffer_size = 64M
-- 定义log buffer空间大小,建议不要超过128M;
innodb_max_dirty_pages_pct = 85
-- 控制在buffer pool中脏页数量的比例,当达到指定的比例就进行checkpoint操作,将脏页信息进行落盘
innodb_lock_wait_timeout = 10
-- 主要是控制行锁的等待超时时间,一般控制在10s内
innodb_open_files = 63000
-- 表示定义最多打开文件句柄的个数,数据库每次访问一个表(即打开一个文件),都会占用一定的文件句柄数量
innodb_page_cleaners = 4
-- 表示和线程有关的优化(可以忽略)
innodb_sort_buffer_size = 64M
-- 表示做排序时利用的缓冲区大小
innodb_print_all_deadlocks = 1
-- 表示将死锁的日志全部记录下来
innodb_rollback_on_timeout = ON
-- 表示当到达超时时间,会自动解决死锁事务
innodb_deadlock_detect = ON
-- 表示开启死锁检测功能(默认开启)
-- 表示和死锁检测和分析有关的参数
-- 对于死锁概念的资料参考:https://blog.csdn.net/java1527/article/details/127105144
|
04 数据库复制相关优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| # 主从复制相关优化参数
relay_log= db-01-relay-bin
relay_log_basename = /data/3306/data/db-01-relay-bin
relay_log_index = /data/3306/data/db-01-relay-bin.index
max_relay_log_size = 500M
relay_log_purge = ON
relay_log_recovery = ON
-- 表示和relay log日志相关的配置参数信息
rpl_semi_sync_master_enabled=on
rpl_semi_sync_master_timeout=1000
rpl_semi_sync_master_trace_level=32
rpl_semi_sync_master_wait_for_slave_count=1
rpl_semi_sync_master_wait_no_slave=on
rpl_semi_sync_master_wait_point=after_sync
rpl_semi_sync_slave_enabled=on
rpl_semi_sync_slave_trace_level=32
binlog_group_commit_sync_delay=1
binlog_group_commit_sync_no_delay_count=1000
-- 表示和半同步复制相关的配置参数
gtid_mode = ON
enforce_gtid_consistency = ON
-- 表示和GTID相关的配置参数信息
master_verify_checksum = ON
-- 表示激活主从复制事件校验机制
sync_master_info = 1
-- 表示每个EVENT都要执行刷盘操作,主要影响master info信息(注意不是每个事务!)
-- 参数参考博文资料:https://blog.csdn.net/weixin_39940344/article/details/113275456
skip-slave-start = 1
-- 表示随着数据库服务的启动,自动启动从库线程
-- 参数参考博文资料:https://blog.csdn.net/csdnhsh/article/details/116355191
# read_only = ON
# super_read_only = ON
-- 表示是否设置从库为只读状态
log_slave_updates = ON
-- 表示指定从库的事务更新操作,是否也记录到从库的binlog日志中
server_id = xx
-- 定义主从的实例标识信息
report_host = xxxx
report_port = xxxx
-- 表示是否允许主库探测从库的网络配置信息,主要影响show slave hosts命令的输出
-- 参数参考博文资料:http://04007.cn/article/527.html
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 4
-- 表示设置从库的多线程复制,可以对单个事务中的语句进行多线程回放
master_info_repository = TABLE
relay_log_info_repository = TABLE
-- 表示定义master info和relay log info以什么方式记录信息
|
05 数据库其他相关优化
1
2
3
4
5
6
| # 数据库客户端配置
[mysql]
no-auto-rehash (等价于mysql -A参数作用)
-- 默认每次连接数据库服务会扫描数据库中所有元数据信息,可以利用此参数关闭扫描功能,有效节省扫描过程占用的内存资源;
pager less
-- 开启数据库输出信息过滤功能
|
1.19.5 数据库服务开发规范要求#
01 数据库开发字段规范
每个表建议在30个字段以内;
需要存储emoji字符时,则选择utf8mb4字符集;
机密数据信息,需要进行加密后再存储;
整型数据类型,默认加上UNSIGNED;
存储IPv4地址建议用INT UNSIGNE只存储数字信息,查询时在利用INET_ATON(),INET_NTOA()函数转换;
如果遇到BLOB、TEXT大字段单独存储表或者附件形式存储;
选择尽可能小的数据类型,用于介绍磁盘和内存空间;
存储浮点数,可以放大倍数存储;
每个表必须有主键,INT/BIGINT类型、以及自增作为主键,分布式架构使用sequence序列生成器保存;
表中每个列使用not null或者增加默认值;
02 数据库开发语句规范(SQL)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| # 01 去掉不必要的括号
before:
((a AND b) AND c OR (((a AND B)) AND ((c AND d))))
after
(a AND b AND c) OR (a AND b AND c AND d)
# 02 去掉重叠条件
before:
(a<b AND b=c) AND a=5
after
b>5 AND b=c AND a=5
before
(b>=5 AND B=5) OR (b=6 AND 5=5) OR (B=7 AND 5=6)
after
b=5 OR b=6
# 03 避免使用not in、not exists、<>、like %%
# 04 多表连接,小表驱动大表
# 05 减少临时表应用,优化order by、group by、uninon、distinct、join等
# 06 减少语句查询范围,精确查询条件
# 07 多条件,符合联合索引最左原则
# 08 查询条件减少使用函数、拼接字符等条件、条件隐式转换
# 09 union all 替代 union
# 10 减少having子句使用
# 11 如非必要不使用for update语句(会加表级别意向锁)
# 12 update和delete,开启安全更新参数
# 13 减少insert ... select 语句应用
mysql > create table city_bak like city;
mysql > desc city_bak;
mysql > insert into city_bak select * from city; (会对原有city表进行加锁,建议加条件扫描)
# 14 使用load替代insert录入大数据(会产生大量的意向锁)
# 15 导入大量数据时,可以禁用索引、增大缓冲区、增大redo文件和buffer,关闭autocommit、RC级别可以提高效率
# 16 优化limit,最好业务逻辑中先获取主键ID,再基于ID进行查询
limit 5000000,10
before
select * from t1 where num > 10 limit 5000000,10;
after
select id from t1 where num > 10 limit 5000000,10;
select id from t1 where id;
# 17 DDL执行前要审核
# 18 多表连接语句执行前要看执行计划
|
1.19.6 数据库服务索引相关优化#
非唯一索引按照 ‘i_字段名称_字段名称[_字段名]’ 进行命名
是唯一索引按照 ‘u_字段名称_字段名称[_字段名]’ 进行命名
索引名称使用小写
联合索引中的字段数不超过5个
唯一键由3个以下字段组成,并且字段都是整型时,使用唯一键作为组合主键
没有唯一键或者唯一键不符合上面的条件时,使用自增id作为主键
唯一键不能和主键重复
索引选择度高的列作为联合索引最左条件
ORDER BY、GROUP BY、DISTINCY的字段需要添加在索引的后面,构建联合索引
单张表的索引数量控制在5个以内,若单张表多个字段在查询需求上都要单独用到索引,需要经过DBA评估;
查询性能问题无法解决的,应从产品设计上进行重构
使用EXPLAN判断SQL语句是否合理使用索引,尽量避免extra列出现:Using File Sort,Using Temporary;
UPDATE DELETE 语句需要根据where条件添加索引;
对长度大于50的VARCHAR字段建立索引时,按需求恰当的使用前缀索引,或使用其他方法;
下面的表增加一列url_crc32,然后对url_crc32建立索引,减少索引字段的长度,提高效率;
1
2
3
4
5
| create table all_url(
ID INT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
url varchar(255) not null default 0,
url_crc32 int unsigned not null
index idx_url(url_crc32));
|
合理创建联合索引(避免冗余),(a,b,c)相当于(a),(a,b),(a,b,c)
合理利用覆盖索引,减少回表次数;
减少冗余索引和使用率较低的索引;
1.19.7 数据库服务事务及锁优化#
锁是计算机协调多个进程或纯线程并发访问某一资源的机制。
在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。
如何保证数据并发访问的一致性、有效性是所在有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
01 数据库锁知识基本概念
1)共享锁和排它锁:
InnoDB实现了两种标准行级锁,一种是共享锁(share lock S锁),另一种是独占锁或者叫排它锁(exclusive locks X锁)
S锁允许当前持有该锁的事务读取行;
X锁允许当前持有该锁的事务更新或删除行;
S锁应用特性:
如果事务T1持有了行r上的S锁,则其他事务可以同时持有行r的S锁,但是不能对行r加X锁;
X锁应用特性:
如果事务T1持有了行r上的X锁,则其他任何事务不能持有行r的X锁,必须等待T1在行r上的X锁释放;
如果事务T1在行r上保持S锁,则另一个事务T2对行r的锁的请求按如下方式处理:
T2可以同时持有S锁;
T2如果想在行r上获取X锁,必须等待其他事务对该行添加的S锁或X锁的释放
2)意向锁-Intention Locks:
InnoDB支持多种颗粒度的锁,允许行级锁和表级锁的共存;
InnoDB使用意向锁来实现多个粒度级别的锁定,意向锁属于表级锁,表示table中的row所需要的锁(S锁或X锁)的类型;
例如:可以通过以下命令在指定的表上加上共享锁或者独占锁
1
2
3
4
5
6
| lock tables 表名 read;
-- 该表可以读,不能ddl 和 dml 中增删改,只能读取表数据
lock tables 表名 write;
-- 既不能读,也不能写
mysql> show open tables like '%city%';
-- 共享锁和排他锁查看;
|
与 FTWRL(全局的读锁)类似,可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。
需要注意,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的对象操作;
举个例子:
如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句;则其他线程写 t1、读写 t2 的语句都会被阻塞。
同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。连写 t1 都不允许,自然也不能访问其他表。
在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。
而对于 InnoDB 这种支持行锁的引擎,一般不使用 lock tables 命令来控制并发,毕竟锁住整个表的影响面还是太大
意向锁分为意向共享锁(IS锁)和意向排它锁(IX锁);
IS锁表示当前事务意图在表中的行上设置共享锁,下面语句执行时会首先获取IS锁,因为这个操作在获取S锁;
1
2
3
4
| select ... lock in share mode
-- 显示设置方法
select * from performance_schema.data_locks\G
-- 查看方法
|
IX锁表示当前事务意图在表中的行上设置排它锁,下面语句执行时会首先获取IX锁,因为这个操作在获取X锁;
1
2
3
4
| select ... for update
-- 显示设置方法
select * from performance_schema.data_locks\G
-- 查看方法
|
在InnoDB存储引擎中,事务要获取某个表上的S锁和X锁之前,必须先分别获取对应的IS锁和IX锁;
锁的兼容矩阵如下:
| 兼容性 | X | IX | S | IS |
|---|
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 兼容 |
| S | 不兼容 | 不兼容 | 兼容 | 兼容 |
| IS | 不兼容 | 兼容 | 兼容 | 兼容 |
按照上面的兼容性,如果不同事务之间的锁兼容,则当前加锁事务可以持有锁,如果有冲突则会等待其他事务的锁释放;
如果一个事务请求锁时,请求的锁与已经持有的锁冲突而无法获取时,互相等待就可能会产生死锁;
意向锁不会阻止除了全表锁定请求之外的任何锁请求,意向锁的主要目的是显示事务正在锁定某行或者正意图锁定某行;
02 数据库InnoDB引擎中的锁
数据库数据锁介绍-Innodb row lock
行级锁,也称为记录锁,顾名思义就是在记录上加的锁;只不过行级锁也分成了各种类型;
在InnoDB存储引擎中,常见的锁有Record锁、gap锁、next-key锁、插入意向锁(Insert Intention Lock)、自增锁等;
下面会对每一种锁给出一个查看锁的示例:
相关锁知识学习准备:
1)测试用表创建
示例的基础是一个只有两列的数据库表:
1
2
3
4
5
6
7
| create table test (
id int(11) not null,
code int(11) not null,
primary key(id),
key(code)
) engine=InnoDB default charset=utf8mb4;
insert into test(id,code) values(1,1),(10,10);
|
数据表test只有两列,id是主键索引,code是普通索引(注意一定不要是唯一索引),并初始化两条数据记录,分别是(1,1),(10,10)
这样,后面验证唯一键索引就可以使用id列,验证普通索引(非唯一键二级索引)时就使用code列;
2)查看锁状态的方式
要看到锁的使用情况,必须手动开启多个事务,其中一些锁的状态的查看则必须使锁处于waiting状态;
这样才能在mysql的引擎状态日志中看到锁的应用情况:
1
| show engine innodb status;
|
这个命令能显示最近几个事务的状态、查询和写入情况等信息。当出现死锁时,命令能给出最近的死锁明细;
记录锁-Record Locks
1)Record锁概述介绍
Record Lock是对索引记录的锁定;记录锁有两种模式:S模式和X模式;
例如:
1
| select id from test where id=10 for update;
|
以上语句表示防止任何其他事务插入、更新或者删除id=10的行;
记录锁始终只锁定索引,即使表没有建立索引,innodb也会创建一个隐藏的聚簇索引(隐藏的递增主键索引);
并使用此索引进行记录锁定;
2)查看记录锁信息
开启第一个事务,不提交,测试完之后回滚:
1
2
3
4
5
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> update test set id=2 where id=1;
Quer y OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
|
事务加锁情况:
1
2
3
4
5
6
7
8
| mysql> show engine innodb status\G
...
-------------------
TRANSACTIONS
-------------------
---TRANSACTION 8790, ACTIVE 85 sec
2 lock struct(s), heap size 1128, 1 row lock(s), undo log entries 2
MySQL thread id 9, OS thread handle 140065464329984, query id 74 localhost root
|
可以看到有一行被加了锁。由上文对锁的描述可以推测出,update语句给id=1这一行加了一个X锁;
特殊说明:
X锁广义上是一种抽象意义的排它锁,即锁一般分为X模式和S模式,狭义上指row或者index上的锁,而Record锁是索引上的锁;
为了不修改数据,可以用select…for update语句,加锁行为和update、delete是一样的,insert加锁机制较为复杂,后面介绍
第一个事务保持原状,不要提交或者回滚,现在开启第二事务:
1
2
3
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> update test set id=3 where id=1;
|
执行update时,sql语句的执行被阻塞了。查看下事务状态:
1
2
3
4
5
6
7
8
9
10
| mysql> show engine innodb status\G
...
------- TRX HAS BEEN WAITING 4 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 47 page no 4 n bits 72 index PRIMARY of table `oldboy`.`test` trx id 8791 lock_mode X locks rec but not gap waiting
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000002256; asc "V;;
2: len 7; hex 01000000bf02aa; asc ;;
3: len 4; hex 80000001; asc ;;
------------------
|
通过以上操作,可以看到了这个锁的状态。状态标题是"事务正在等待获取锁”,描述中的lock_mode X locks rec but not gap ;
就是本小结知识点中的record记录锁,直译一下"X锁模式锁住了记录";后面还有依据but not gap 意思是只对record本身加锁,
并不对间隙加锁,间隙锁的叙述见下面知识点内容。
间隙锁-Gap Locks
1)Gap锁概述介绍
间隙锁作用在索引记录之间的间隔,又或者作用在第一个索引之前,最后一个索引之后的间隙。不包括索引本身;
例如:
1
| select c1 from t where c1 between 10 and 20 for update;
|
这条语句阻止其他事务插入10和20之间的数字,无论这个数字是否存在;
间隙可以跨越0个,单个或多个索引值,间隙锁是性能和并发权衡的产物,只存在于部分事务隔离级别中;
1
| select * from table where id=1;
|
唯一索引可以锁定一行,所以不需要间隙锁锁定。如果列没有索引或者具有非唯一索引,该语句会锁定当前索引前的间隙;
在同一个间隙上,不同的事务可以持有上述兼容/冲突表中冲突的两个锁。
例如:事务T1现在持有一个间隙S锁,T2可以同时在同一个间隙上持有间隙X锁;
允许冲突的锁在间隙上锁定的原因是,如果从索引中清除一条记录,则由不同事务在这条索引记录上的加间隙锁的动作必须被合并;
InnoDB中的间隙锁的唯一目的是防止其他事务插入间隙。
间隙锁是可以共存的,一个事务占用的间隙锁不会阻止另一个事务获取同一个间隙上的间隙锁;
说明:如果事务隔离级别改为RC,则间隙锁会被禁用。
2)查看间隙锁信息
按照官方文档,where子句查询条件是唯一键且指定了值时,只有record锁,没有gap锁;
如果where语句指定了范围,gap锁是存在的;
下面测试验证一下当指定非唯一键索引的时候,gap锁的位置,按照官方文档的说法,会锁定当前索引及索引之前的间隙;
说明:指定了非唯一键索引,例如code=10,间隙锁仍然存在
开启第一个事务,锁定一条非唯一的普通索引记录:
1
2
3
4
5
6
7
8
9
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> select * from test where code=10 for update;
+----+------+
| id | code |
+----+------+
| 10 | 10 |
+----+------+
1 row in set (0.00 sec)
|
由于预存了两条数据row(1,1)和row(10,10),此时这个间隙应该是1<gap<10。
下面我们先插入row(2,2)来验证下gap锁的存在,再插入row(0,0)来验证gap的边界;
解释说明:
按照间隙锁的官方文档定义,select * from test where code=10 for update; 会锁定code=10这个索引;
并且会锁定code<10的间隙
开启第二个事务,在code=10之前的间隙中插入一条数据,看下这条数据是否能够插入:
1
2
3
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> insert into test values(2,2);
|
插入的时候,执行被阻塞,查看引擎状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
| mysql> show engine innodb status\G
...
---TRANSACTION 8794, ACTIVE 3 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 2 lock struct(s), heap size 1128, 1 row lock(s), undo log entries 1
MySQL thread id 14, OS thread handle 140065464329984, query id 159 localhost root update
insert into test values(2,2)
------- TRX HAS BEEN WAITING 3 SEC FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 47 page no 5 n bits 72 index code of table `oldboy`.`test` trx id 8794 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 4; hex 8000000a; asc ;;
------------------
|
插入语句被阻塞了,lock_mode X locks gap before rec,由于第一个事务锁住了1到10之间的gap,需要等待获取锁之后才能插入;
如果在开启一个事务,插入(0,0)
1
2
3
4
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> insert into test values(0,0);
Quer y OK, 1 row affected (0.00 sec)
|
可以看到:指定的非唯一键索引的gap锁的边界是当前索引到上一个索引之间的gap;
最后给出锁定区间的示例,首先插入一条记录(5,5):
1
2
| mysql> insert into test values (5,5);
Quer y OK, 1 row affected (0.00 sec)
|
开启第一个事务:
1
2
3
4
5
6
7
8
9
10
11
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> select * from test where code between 1 and 10 for update;
+----+------+
| id | code |
+----+------+
| 1 | 1 |
| 5 | 5 |
| 10 | 10 |
+----+------+
3 rows in set (0.00 sec)
|
第二个事务,试图去更新code=5的行;
1
2
3
| mysql> begin;
Quer y OK, 0 rows affected (0.00 sec)
mysql> update test set code=4 where code=5;
|
执行到这里,如果第一个事务不提交或者回滚的话,第二事务一直等待直至mysql中设定的超时时间;
下一键锁-Next-key Locks
1)Next-key锁概述介绍
Next-key锁实际上是Record锁和gap锁的组合,Next-Key锁是在下一个索引记录本身和索引之前的gap加上S锁或是X锁;
如果是读就加上S锁,如果是写就加上X锁;
默认情况下,InnoDB的事务隔离级别为RR,系统参数innodb_locks_unsafe_for_binlog的值为false;
InnoDB使用next-key锁对索引进行扫描和搜索,这样就读取不到幻象行,避免了幻读的发生;
解释说明:
幻读是指在同一事务下,连续执行两次同样的SQL语句,第二次的SQL语句可能会返回之前不存在的行;
当查询的索引是唯一索引时,Next-key lock会进行优化,降级为Record Lock,此时Next-key lock仅仅作用在索引本身,
而不会作用于gap和下一个索引上;
2)查看下一键锁信息
Next-key锁的作用范围:
如上述例子,数据表test初始化了row(1,1),row(10,10),然后插入了row(5,5),数据表内容如下:
1
2
3
4
5
6
7
8
9
| mysql> select * from test;
+----+------+
| id | code |
+----+------+
| 1 | 1 |
| 5 | 5 |
| 10 | 10 |
+----+------+
3 rows in set (0.00 sec)
|
由于id是主键,唯一索引,mysql会做优化,因此使用code这个非唯一键的二级索引来举例说明;
对于code,可能的next-key锁的范围是:
1
| (-∞,1] (1,5] (5,10] (10,+∞)
|
开启第一个事务,在code=5的索引上请求更新:
1
2
3
4
5
6
7
8
9
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> select * from test where code=5 for update;
+----+------+
| id | code |
+----+------+
| 5 | 5 |
+----+------+
1 row in set (0.00 sec)
|
之前在gap锁的知识点中介绍了,code=5 for update会在code=5的索引上加一个record锁,还会1<gap<5的间隙上加gap锁;
此时不再验证,直接插入一条(8,8):
1
2
3
| mysql> start transaction;
Quer y OK, 0 rows affected (0.00 sec)
mysql> insert into test values(8,8);
|
insert处于等待执行的状态,这就是next-key锁生效而导致的结果;
第一个事务,锁定了区间(1,5],由于RR的隔离级别下next-key锁处于开启生效状态,又锁定了(5,10]区间;
所以插入SQL语句的执行被阻塞;
解释说明:
在这种情况下,被锁定的区域是code=5前一个索引到它的间隙,以及next-key的区域;
code=5 for update对索引的锁定用区间表示,gap锁锁定了(1,5),record锁锁定了(5)索引记录,next-key锁锁住了(5,10];
也就是说整个(1,10]的区间被锁定了
由于是for update,所以这里的锁都是X锁,因此阻止了其他事务中带有冲突锁定的操作执行
如果在第一个事务中,执行了code>8 for update,在扫描过程中,找到了code=10,
此时就会锁住10之间的间隙(5到10之间的gap),10本身(record),和10之后的间隙(next-key)
此时另一个事务插入(6,6),(9,9)和(11,11)都是不允许的,只有在前一个索引5及5之前的索引和间隙才能执行插入;
更新和删除操作也会被阻塞。
插入意向锁
插入意向锁在行插入之前由INSERT设置一种间隙锁,是意向排它锁的一种。
在多事务同时写入不同数据至同一索引间隙时,不会发生锁等待,事务之间互相不影响其他事务的完成,这和间隙锁的定义是一致的;
假设一个记录索引包含4和7,其他不同的事务分别插入5和6,此时只要行不冲突,插入意向锁不会互相等待,可以直接获取。
自增锁
自增锁(auto-inc locks)是事务插入时自增列上特殊的表级别的锁,最简单的一种情况;
如果一个事务正在向表中插入值,则任何其他事务必须等待,以便第一个事务插入的行接收连续的主键值;
一般把主键设置为auto_increment的列,默认情况下这个字段的值为0,
InnoDB会在auto_increment修饰下的数据列所关联的索引末尾设置独占锁;
在访问自增计数器时,InnoDB使用自增锁,但是锁定仅仅持续到当前SQL语句的末尾,而不是整个事务的结束;
毕竟自增锁是表级别的锁,如果长期锁定会大大降低数据库的性能;
由于是表锁,在使用期间,其他会话无法插入表中
03 数据库闩锁介绍-latch
latch主要用于管理对共享内存资源的并发访问,例如:操作缓冲池汇总的LRU列表,删除、添加、移动LRU列表中的元素;
为了保证一致性,必须有锁的接入,这就是latch锁;
latch锁和一般的lock锁之间的区别为:
| 区别 | lock | latch |
|---|
| 锁定对象 | 事务(SQL操作流程) | 线程 |
| 保护对象 | 数据库对象(库 表 行 索引 表空间 数据页等) | 所有共享内存数据结构 |
| 生命周期 | 整个操作周期 | 临界资源-mutex(互斥量) |
| 锁定模式 | MDL(元数据锁)、Table、Record、Gap(间隙锁)、NextLock | 、意向rw-latch、 |
名词解释:临界资源
有的资源一次只允许一个进程使用,在它未用完之前,不允许其他进程使用,这类资源被称为临界资源,也称为互斥资源。
输入机、打印机以及变量、数据、表格、队列等都属于临界资源。
其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测的机制。
读写锁:
读锁(共享锁)
当MySQL的一个进程(sessionA)为某一表开启读锁后,其他的进程包含自身都没有权利去修改这张表的内容。
但是所有的进程还是可以读出表里面的内容的
sessionA可以继续对该数据表加写锁,其他session也可以对该数据表继续加读锁但不能加写锁,直到sessionA释放共享锁权限
当其他的session对这张表进行更新操作时,该线程进入阻塞,直至sessionA释放锁
sessionA没有释放锁之前不能对其他表进行任何操作
写锁(排他锁)
当MySQL的某一个进程(sessionA)在对某一张表开启写锁后,sessionA只能对该表进行读取或修改,
在没有释放锁之前不能对其他表进行任何操作
其他session既不能读取也不能修改该表,更不能对该表加任何类型的锁,直到sessionA释放写锁
查看latch争用的类型信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| # 模拟存储数据信息操作
mysql> source ~/t100w_oldboy.sql
# 查看mutex的互斥争用信息:
mysql> show engine innodb mutex;
+----------+-------------------------------------+------------+
| Type | Name | Status |
+----------+-------------------------------------+------------+
| InnoDB | rwlock: dict0dict.cc:2678 | waits=1 |
| InnoDB | rwlock: dict0dict.cc:1184 | waits=13 |
| InnoDB | rwlock: log0log.cc:844 | waits=35 |
| InnoDB | sum rwlock: buf0buf.cc:788 | waits=16 |
+----------+-------------------------------------+------------+
1 row in set (0.01 sec)
-- 表示进行sum统计读写锁的总占用时间,为等待状态16毫秒,并输出造成锁等待的源码文件和位置信息;
-- 通过源码文件的信息,可以推断分析出,可能在写内存信息(buffer pool),可能是某个内存链位置点或内存页信息被占用
# 可以通过第三方工具分析堆栈信息:
pstack -p 'pidof mysqld' > /tmp/aa.txt
pt-pmp /tmp/aa.txt|more
|
分析latch争用的发生时间:
当A线程访问x内存链表时,B线程排队等待x内存链表解锁,此时CPU发现B线程处于等待状态,所以会将B线程从CPU中踢出;
A线程进行访问锁链的时间,就是A线程找数据的时间;
由于B线程知道A线程很快就会结束,所以B不去排队,而是做spin操作(空转CPU),然后再去看内存数据结构,A线程是否已解锁;
当B线程转了一圈后,在B线程spin操作的时间段中,C线程进来了,连续多次的spin操作后,即产生了os waits;
操作系统会将B线程从CPU中踢出;
说明:latch锁争用的表面现象为,CPU在争用期间繁忙、IO很闲、没有做实际的事情;
监控latch争用的具体情况:(主要关注较为严重的争用)
1
2
3
4
5
6
7
8
9
10
11
12
| mysql> show engine innodb status\G
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reser vation count 0
OS WAIT ARRAY INFO: signal count 1
RW-shared spins 0, rounds 0, OS waits 0
RW-excl spins 0, rounds 0, OS waits 0
RW-sx spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx
-- rounds:意思是每次询问旋转的次数;
-- os waits:表示sleep,当突然增长的比较快的时候,说明latch争用的比较严重;
|
注意:只要监控信息中的 OS waits/rounds > 5%,就表示latch锁的争用非常严重了;
导致latch争用的发生原因:
内存访问太过于频繁(不停的找),因为早期数据库版本中,是不存在AHI技术概念;
list链太长(链上挂10000个块,被持有的几率太大)
可以利用以下方式,降低latch争用:
优化SQL语句,从而降低对内存读的数量;
增加数据库instances的数量,即拆分多个内存区域;
1
2
3
4
5
6
| mysql> show variables like '%buffer%';
+--------------------------------------------+----------------+
| Variable_name | Value |
+--------------------------------------------+----------------+
| innodb_buffer_pool_instances | 1 |
+--------------------------------------------+----------------+
|
04 数据库全局锁介绍-GRL
GRL(Global Read Lock)全局锁也可以理解为是全局读锁;
1
2
3
4
| # 主要的加锁方式为:FTWRL
> flush tables with read lock;
# 主要的解锁方式为:
> unlock tables;
|
经常在进行数据备份时,mysqldump –master-data或者xtrabackup(8.0之前早期版本)等备份出现全局锁;
mysqldump –master-data备份时实际上是做了四件事:
| 序号 | 行为 | 锁机制影响 |
|---|
| 01 | 记录binlog位置点 | 备份期间不让所有事务提交 |
| 02 | 实现FTWRL锁定 | 备份期间不让新的修改进入 |
| 03 | unlock tables | 备份期间非Innodb表的表结构备份完毕后,会进行解锁表操作 |
| 04 | snapshot innodb | 备份期间需要对数据信息实现快照方式备份 |
xtrabackup备份数据时,备份非InnoDB表数据时,会FTWRL,备份完毕后,会unlock tables;
xtrabackup备份数据时,备份InnoDB表数据时,会备份checkpoint后的数据页,并记录redo变化,可以允许DML,不允许DDL;
GRL全局锁实质是属于MDL(matedatalock)层面的元数据锁;
在全局锁GRL出现加锁期间,会阻塞所有事务写入,阻塞所有已有事务commit;
全局锁的控制机制,是由以下时间参数信息进行的控制:
1
2
3
4
5
6
7
| mysql> select @@lock_wait_timeout;
+-----------------------------+
| @@lock_wait_timeout |
+-----------------------------+
| 31536000 |
+-----------------------------+
1 row in set (0.00 sec)
|
检测是否存在全局锁GRL方法:
1
2
3
4
5
6
7
8
9
| # 记录加锁过程信息
mysql> update performance_schema.setup_instruments set ENABLED='Yes', TIMED='Yes' where NAME='wait/lock/metadata/sql/mdl'
-- 激活GRL锁检测功能(8.0版本之后默认激活了)
mysql> select * from performance_schema.metadata_locks;
mysql> select object_schema,object_name,lock_type,lock_duration,lock_status,owner_thread_id,owner_event_id from performance_schema.metadata_locks;
-- 查看GRL锁定的相关信息,其中granted表示请求到了GRL锁,而若变为pending状态,表示处于阻塞状态;
# 记录加锁过程信息(5.7)
mysql> show processlist;
mysql> select * from sys.schema_table_lock_waits;
|
GRL锁机制案例模拟:
案例01:在数据库 5.7环境中,利用xtrabackup/mysqldump备份时数据库出现hang状态,所有查询都不能进行;
1
2
3
4
5
6
7
8
| # 会话01:模拟一个大的查询或事务
mysql> select *,sleep(100) from city where id<10 for update;
# 会话02:模拟备份时的FTWRL
mysql> flush tables with read lock;
-- 此时发现命令被阻塞
# 会话03:发起正常查询,发现被阻塞
mysql> select * from world.city where id=1 for update;
mysql> show processlist;
|
结论:备份数据时,一定要选择业务不繁忙期间,否则有可能会阻塞正常的业务操作;
案例02:5.7数据库进行innobackupex备份全库,造成进程死了(FTWRL后),mysql里就是全库读锁,后边insert全被阻塞了;
1
2
3
4
5
6
7
8
9
10
11
12
| # 会话01:模拟一个大的查询或事务
mysql> select *,sleep(100) from city where id<10;
mysql> show processlist;
# 会话02:模备份时的FTWRL
mysql> flush tables with read lock;
-- 保证命令执行成功
mysql> unlock tables;
-- 解除命令锁定操作后,后续修改和插入操作也可以成功
# 会话03:发起正常查询,发现被阻塞
mysql> select * from world.city where id=1 for update;
mysql> select * from world.city where id=1
-- 要进行的修改操作是不行的,但是所有简单查询操作是可以进行的
|
05 数据库表级锁介绍-Table Lock
数据库中表级锁应用-MyISAM
数据库的表级锁表示对相应的整表进行上锁操作,避免并发操作同一个表的产生冲突问题,但主要针对MyISAM引擎才经常使用表级锁;
MySQL表级锁有两种模式:表共享锁(Table Read Lock)和表独占写锁(Table Write Lock);
对MyISAM的读操作,不会阻塞其他用户对同一表请求,但会阻塞对同一表的写请求;
对MyISAM的写操作,则会阻塞其他用户对同一表的读和写操作;
MyISAM表的读操作和写操作之间,以及写操作之间是串行的。
| 当前锁模式 | 其他会话读操作 | 其他会话写操作 |
|---|
| 读锁 | 可以 | 禁止 |
| 写锁 | 禁止 | 禁止 |
当一个线程获得对一个表的写锁后,只有持有锁线程可以对表进行更新操作。其他线程的读、写操作都会等待,直到锁被释放为止。
表级锁设置方法:
MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁
MyISAM 在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁
这个过程并不需要用户干预,因此用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁。
显式加锁基本上都是为了方便而已,并非必须如此。
数据库中表级锁应用-Innodb
Innodb存储引擎支持表级锁,也支持行级锁;
表级锁应用概述:
表级锁锁定粒度粗,占用资源较少,不过有时只是仅仅需要锁住几条记录时,如果使用表级锁,效果上相当于为表中的所有记录加锁;
将会降低数据库服务的事务并发处理性能;
行级锁应用概述:
表级锁锁定粒度细,可以实现更精准的并发控制,但是占用资源较多;
表级锁的加锁的方式:(知识补充)
给表加的锁可以分为共享锁(S)和独占锁(X)
给表加S锁:如果一个事务给表加了S锁,那么:
别的事务可以继续获得该表的S锁;
别的事务可以继续获得该表中某些记录的S锁;
别的事务不可以继续获得该表的X锁;
别的事务不可以继续获得该表中某些记录的X锁;
给表加X锁:如果一个事务给表加了X锁(意味着该事务要独占这个表),那么
别的事务不可以继续获得该表的S锁;
别的事务不可以继续获得该表中某些记录的S锁;
别的事务不可以继续获得该表的X锁;
别的事务不可以继续获得该表中某些记录的X锁;
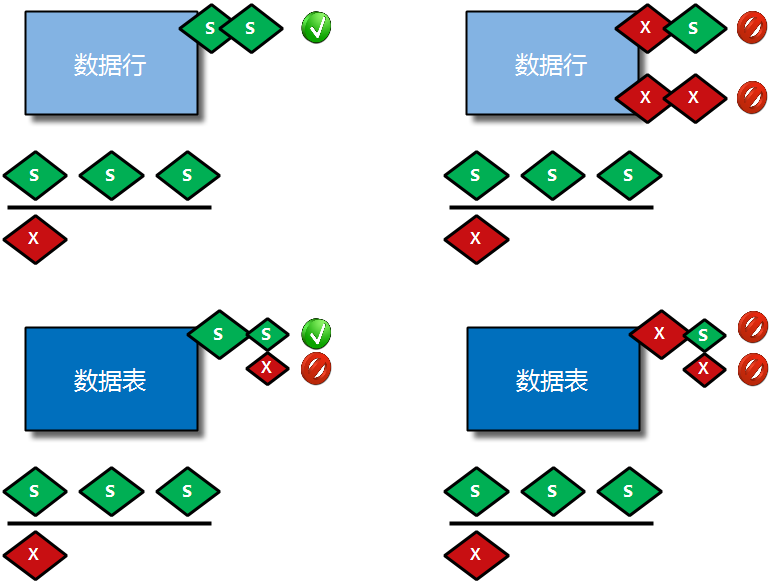
了解完表和行加上的S锁和X锁的应用后,还需要考虑两种特殊情况:
如果相对数据表整体加上S锁,首先需要确保数据表中没有正在修改的行,如果有正在修改的行,则需要等待行修改完毕再加表的S锁;
如果想对数据表整体加上X锁,首先需要确保数据表中没有正在处理的行,如果有正在处理的行,则需要等待行处理完毕再加表的X锁;
但是,如果每次给数据表加锁时,都对表中的每行数据进行检查,确认是否有行级锁信息,这个工作的代价实在是太大了,
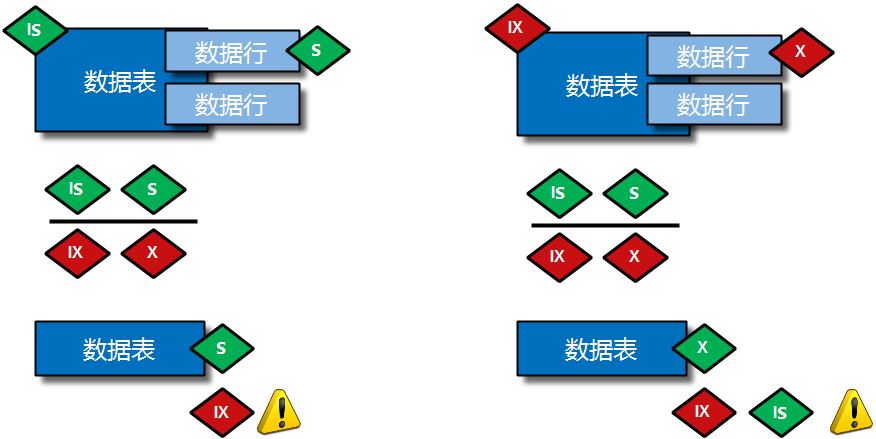
因此,为了解决以上的两种特殊情况问题,Innodb设计的过程中添加了一种称为意向锁(Intention Lock)的东西
意向共享锁(Intention Shared Lock):简称IS锁
当事务准备在某条记录上加S锁时,需要先在表级别加上一个IS锁:
意向独占锁(Intention Exclusive Lock):简称IX锁
当事务准备在某条记录上加X锁时,需要先在表级别加上一个IX锁;
表级别的锁的兼容性总结:
| 兼容性 | X | IX | S | IS |
|---|
| X | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
| IX | 不兼容 | 兼容 | 不兼容 | 兼容 |
| S | 不兼容 | 不兼容 | 兼容 | 兼容 |
| IS | 不兼容 | 兼容 | 兼容 | 兼容 |
Innodb表级锁的应用类别:
表级别的S锁、X锁:
在对某个表执行select、insert、delete、update语句时,Innodb存储引擎是不会为这个表添加表级别的S锁或者X锁;
其实,Innodb存储引擎提供的表级S锁或者X锁相当鸡肋,只会在一些特殊情况下(比如在系统崩溃恢复时)用到;
不过还是可以手动获取下,需要在系统变量 autocommit=0、innodb_table_locks=1时,手动获取数据表的S锁或者X锁;
可以按照下面语句执行,最终获取表级的S锁或X锁:
1
2
3
4
| LOCK TABLE t READ
-- innodb存储引擎会对表t加表级别的S锁
LOCK TABLE t WRITE
-- innodb存储引擎会对表t加表级别的
|
需要注意尽量避免在使用Innodb存储引擎的表上使用LOCK TABLES这样的手动锁表语句,因为对表并不会有什么额外保护;
反而只是降低并发能力。
InnoDB的厉害之处是实现了更细粒度的行级锁,关于表级别的S锁和X锁了解即可;
表级别的IS锁、IX锁:
当对使用InnoDB存储引擎的表的某些记录加S锁之前,需要先在表级别加上一个IS锁;
当对使用InnoDB存储引擎的表的某些记录加X锁之前,需要先在表级别加上一个IX锁;
IS锁和IX锁的使命只是为了后续在加表级别的S锁和X锁时,判断表中是否已经被加锁的记录,避免遍历查看表中有没有上锁的记录;
表级别的AUTO-INC锁:
在使用MySQL的过程中,可以为表的某个列添加AUTO_INCREMENT属性,之后在插入记录时,可以不指定该列的值;
系统会自动为它赋予递增的值;
系统自动给AUTO_INCREMENT修饰的列进行递增赋值的实现方式主要有下面两个:
01 采用AUTO-INC锁:
在执行插入语句时就加一个表级别的AUTO-INC锁,然后为每条待插入记录的AUTO_INCREMENT修饰的列分配递增的值;
在该语句执行结束后,再把AUTO-INC锁释放掉;
这样一来,一个事务在持有AUTO-INC锁的过程中,其他事务的插入语句都要被阻塞,从而保证一个语句中分配的递增是连续的;
若插入语句在执行前并不确定具体要插入多少条记录(无法预计即将插入记录的数量);
比如使用:insert…select、replace…select或者Load data这种插入语句,一般使用AUTO-INC锁为自增列生成对应的值。
说明:AUTO-INC锁的作用范围只是单个插入语句,插入语句执行完成后,这个锁就被释放了;
02 采用轻量级的锁
在为插入语句生成AUTO_INCREMENT修饰的列的值时获取这个轻量级的锁,然后在生成本次插入语句需要用到的自增列的值之后;
就把该轻量级锁释放掉,而不需要等到整个插入语句执行完后才释放锁;
如果插入语句在执行前就可以确定具体要插入多少条记录,比如语句执行前就确定要插入2条记录,那么就采用轻量级锁方式;
对自增修饰的列进行赋值,采用这种方式可以避免锁定表,可以提升插入性能。
Innodb存储引擎提供了一个名为innodb_autoinc_lock_mode 的系统变量,用来控制到底使用上述两种方式的哪一种;
当innodb_autoinc_lock_mode的值为0时,一律采用AUTO_INC锁;
当innodb_autoinc_lock_mode的值为2时,一律采用轻量级锁;
当innodb_autoinc_lock_mode的值为1时,采用两种锁混合使用方式;
当innodb_autoinc_lock_mode的值为2时,可能会造成不同事务中插入语句为自增列生成的值是交叉的,可能会影响主从复制;
06 数据库元数据锁介绍-MDL
在对某个表执行一些诸如:alter table、drop table的DDL语句时,其他事务在对这个表并发执行增删改查的语句,会发生阻塞;
同理,某个事务在对某个表执行增删改查等语句时,在其他会话中对这个表执行DDL语句也会发生阻塞。
这个过程其实是通过在server层使用一种称为元数据锁(Metadata Lock,MDL)的东西来实现的;
07 数据库数据信息死锁-Dead lock
死锁主要发生在多个并发事务之间出现交叉资源依赖时;类似A会话正在等待B会话事务的解锁,B会话正在等待A会话事务的解锁;
一旦触发了死锁机制,作为InnoDB引擎会自动发现排查死锁的争用情况,识别代价比较低的事务信息,并进行回滚操作;
死锁信息监控以及分析:
1
2
3
4
| mysql >show engine innodb status \G
-- 记录最后一次死锁情况信息
mysql >set global innodb_print_all_deadlocks=1;
-- 将所有死锁情况信息记录到错误日志文件中;(可以在线直接打开)
|
死锁经典案例复盘解析:
在数据库会话一窗口进行的操作信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| # 进行死锁环境准备
mysql> create database test;
mysql> use test;
mysql> create table t1 (id int not null primary key,k1 varchar(20));
mysql> insert into t1 values(1,'a'),(2,'b'),(3,'c'),(4,'d'),(5,'e');
mysql> commit;
# 查看数据信息
mysql> select * from t1;
+----+------+
| id | k1 |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
# 模拟触发死锁问题(A事务从前向后删除 B事务从后向前删除)
mysql> begin;
Quer y OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=1;
Quer y OK, 1 row affected (0.00 sec)
mysql> delete from t1 where id=2;
Quer y OK, 1 row affected (0.00 sec)
mysql> delete from t1 where id=3;
Quer y OK, 1 row affected (0.00 sec)
mysql> delete from t1 where id=4;
Quer y OK, 1 row affected (0.01 sec)
mysql> commit;
Quer y OK, 0 rows affected (0.00 sec)
# 线上业务死锁情况排查
mysql> pager less
mysql> show engine innodb status \G
------------------------
LATEST DETECTED DEADLOCK
------------------------
2023-02-18 17:53:21 140212182464256
*** (1) TRANSACTION:
TRANSACTION 2355, ACTIVE 82 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1128, 3 row lock(s), undo log entries 2
MySQL thread id 20, OS thread handle 140212502341376, query id 2466 localhost root updating
delete from t1 where id=3
-- 死锁构建的第一个事务信息
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 12 page no 4 n bits 72 index PRIMARY of table `test`.`t1` trx id 2355 lock_mode X locks rec but not gap
Record lock, heap no 5 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000004; asc ;;
1: len 6; hex 000000000933; asc 3;;
2: len 7; hex 020000013302dc; asc 3 ;;
3: len 1; hex 64; asc d;;
Record lock, heap no 6 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000005; asc ;;
1: len 6; hex 000000000933; asc 3;;
2: len 7; hex 020000013302b8; asc 3 ;;
3: len 1; hex 65; asc e;;
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 12 page no 4 n bits 72 index PRIMARY of table `test`.`t1` trx id 2355 lock_mode X locks rec but not gap waiting
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000003; asc ;;
1: len 6; hex 000000000932; asc 2;;
2: len 7; hex 01000001410199; asc A ;;
3: len 1; hex 63; asc c;;
*** (2) TRANSACTION:
TRANSACTION 2354, ACTIVE 112 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1128, 4 row lock(s), undo log entries 3
MySQL thread id 22, OS thread handle 140212499687168, query id 2468 localhost root updating
delete from t1 where id=4
-- 死锁构建的第二个事务信息(从而造成事务交叉冲突或依赖)
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 12 page no 4 n bits 72 index PRIMARY of table `test`.`t1` trx id 2354 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000001; asc ;;
1: len 6; hex 000000000932; asc 2;;
2: len 7; hex 01000001410151; asc A Q;;
3: len 1; hex 61; asc a;;
Record lock, heap no 3 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000002; asc ;;
1: len 6; hex 000000000932; asc 2;;
2: len 7; hex 01000001410175; asc A u;;
3: len 1; hex 62; asc b;;
Record lock, heap no 4 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000003; asc ;;
1: len 6; hex 000000000932; asc 2;;
2: len 7; hex 01000001410199; asc A ;;
3: len 1; hex 63; asc c;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 12 page no 4 n bits 72 index PRIMARY of table `test`.`t1` trx id 2354 lock_mode X locks rec but not gap waiting
Record lock, heap no 5 PHYSICAL RECORD: n_fields 4; compact format; info bits 32
0: len 4; hex 80000004; asc ;;
1: len 6; hex 000000000933; asc 3;;
2: len 7; hex 020000013302dc; asc 3 ;;
3: len 1; hex 64; asc d;;
|
在数据库会话二窗口进行的操作信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| # 核实数据信息
mysql> use test;
mysql> select * from t1;
+----+------+
| id | k1 |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
# 模拟触发死锁问题
mysql> begin;
Quer y OK, 0 rows affected (0.00 sec)
mysql> delete from t1 where id=5;
Quer y OK, 1 row affected (0.00 sec)
mysql> delete from t1 where id=4;
Quer y OK, 1 row affected (0.00 sec)
mysql> delete from t1 where id=3;
ERROR 1213 (40001): Deadlock found when tr ying to get lock; tr y restarting transaction
-- 死锁出现,自动对代价小的事务进行回滚;
|
1.19.8 数据库服务架构设计优化#
选择合理架构环境,避免单点故障对数据库服务的影响:
可以选择高可用架构:MHA+ProxySQL+GTID+半同步,MGR+InnoDB Cluster,PXC;
可以选择读写分离架构:ProxySLQ、MySQL-Router
可以选择分布式架构:MyCAT
可以选择缓存服务架构:Redis+sentinel,Redis Cluster,MongoDB RS/MongoDB SHARDING Cluster,ES
1.19.9 数据库服务安全应用优化#
使用普通nologin用户管理MySQL服务进程;
合理授权用户、设置密码复杂度及最小权限,系统表保证只有管理员用户可以访问;
删除数据库服务中的默认匿名用户信息;
锁定数据库服务中的非活动用户信息;
数据库服务尽量不要暴露到互联网中,需要在互联网中暴露数据库服务地址信息时,要明确设置好白名单信息;
替换数据库默认端口,使用SSL远程连接数据库;
对业务程序代码做好扫描检测优化,防止出现SQL注入漏洞情况;
1.21 数据库服务工具应用#
pt(percona-toolkit)工具箱应用安装部署:
1
2
| [root@master ~]# cd /usr/local/
[root@master local]# yum install -y percona-toolkit-3.1.0-2.el7.x86_64.rpm
|
1.20.1 数据库服务工具实践-pt-archiver#
pt-archiver工具比较适合于大量数据信息的归档操作;
比如:亿级的数据大表,当delete批量删除100w左右数据信息时,就可以使用到此工具;
比如:定期按照时间范围进行归档数据表;
官方资料参考:https://docs.percona.com/percona-toolkit/pt-archiver.html
工具使用过程重要参数:
| 序号 | 参数信息 | 解释说明 |
|---|
| 01 | –limit 100 | 每次取100行数据用pt-archive处理 |
| 02 | –txn-size 100 | 设置每100行进行一次事务提交操作 |
| 03 | –where ‘id<3000’ | 设置操作条件 |
| 04 | –progress 5000 | 每处理5000行数据信息,输出一次处理信息的情况 |
| | 输出执行过程及最后的操作统计 |
| 05 | –statistics | |
| | 只要不加上–quiet,默认情况下会输出命令操作的执行过程 |
| 06 | –charset=UTF8 | 指定字符集为UTF8(这个参数最后要加上,否则可能会出现乱码) |
| 07 | –bulk-delete | 批量删除source上的旧数据(例如每次1000行的批量删除操作) |
| 08 | –commit-each | 提交每组提取和归档的行事务 |
说明:需要归档表中至少有一个索引,最好是where条件列信息具有索引;
工具使用案例情况操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| # 将数据表归档到另一个数据表中
mysql> create table test1 like t100w;
-- SQL语句操作实现创建归档表
[root@master ~]# pt-archiver --source h=10.0.0.51,D=test,t=t100w,u=xiaoQ,p=123 --dest h=10.0.0.51,D=test,t=test1,u=xiaoQ,p=123 --where 'id<10000' --no-check-
charset --no-delete --limit=1000 --commit-each --progress 1000 --statistics
# 实践练习环境操作
mysql> create database oldboy;
mysql> use oldboy;
mysql> source ~/t100w_oldboy.sql;
mysql> commit;
mysql> create table test1 like t100w;
mysql> show tables;
+-----------------------+
| Tables_in_oldboy |
+-----------------------+
| t100w |
| test1 |
+-----------------------+
2 rows in set (0.00 sec)
mysql> alter table t100w modify id int not null primary key;
mysql> alter table test1 modify id int not null primary key;
-- pt工具操作练习环境准备
[root@master ~]# pt-archiver --source h=192.168.30.101,P=3307,D=oldboy,t=t100w,u=root,p=123 --dest h=192.168.30.101,P=3307,D=oldboy,t=test1,u=root,p=123 --
where 'id<10000' --no-check-charset --no-delete --limit=1000 --commit-each --progress 1000 --statistics
-- 此操作并不能加快归档或删除操作的速度,只会减少原有业务情况的影响(即大事务切割为小事务操作)
mysql> select * from test1;
-- 进行核查检验数据信息是否迁移归档
# 将数据表中数据信息清理
[root@master ~]# pt-archiver --source h=192.168.30.101,P=3307,D=oldboy,t=t100w,u=root,p=123 --where 'id<10000' --purge --limit=1 --no-check-charset
mysql> select * from oldboy.t100w limit 100;
# 将数据导出到外部文件,但不删除原表中的数据
[root@master local]# pt-archiver --source h=192.168.30.101,P=3307,D=oldboy,t=t100w,u=root,p=123 --where '1=1' --no-check-charset --no-delete --
file="/tmp/archiver.csv"
|
1.20.2 数据库服务工具实践-pt-osc#
pt-osc工具对于修改表结构、索引创建删除比较擅长,pt工具应用不能加快改写速度,但能减少业务影响,主要是锁对业务的影响;
pt-osc工具应用流程:(面试题)
检查更改表是否有主键或唯一键索引信息,并检查是否存在触发器设置;
检查要修改的表结构情况,创建一个临时表,在新表上执行alter table语句;
1
2
| mysql> create table backup like t1;
mysql> alter table backup add telnum char(11) not null;
|
在源表上创建三个触发器分别对于insert update delete操作;
1
| mysql> create trigger ;a xx;b xx;c xx;
|
从源表拷贝数据到临时表,在拷贝过程中,对原表的更新操作也会写入到新建的临时表中;
1
| mysql> insert into backup select * from t1
|
将临时表和源表进行重命名操作rename;(需要利用元数据修改锁,会出现短时间锁表)
删除源表和触发器设置,最终完成表结构信息的修改;
pt-osc工具使用限制:
源表必须有主键或唯一键索引,如果没有工具将停止工作;
如果线上的复制环境过滤器操作过于复杂,工具将无法工作;
如果开启复制延迟检查,但主从延迟时,工具将暂停数据拷贝工作;
如果开启主服务器负载检查,但主服务器负载较高时,工具将暂停操作;
当表使用外键时,如果未使用–alter-foreign-keys-method参数,工具将无法执行;
只支持Innodb存储引擎表,且要求服务器上有该表1倍以上的空闲空间;
pt-osc工具应用alter语句限制:
不需要包含alter table关键字,可以包含多个修改操作,使用逗号分隔:drop column c1;add column c2 int;
不支持rename语句来对表进行重命名操作;
不支持对索引进行重命名操作;
如果删除外键,需要对外键名加下划线,例如删除外键fk_uid,修改语句为”DROP FOREIGN KEY _fk_uid”
说明:一般使用pt-osc主要用于对索引或表结构,进行添加或删除操作;默认在数据库8.0之后,也可以不使用工具直接修改;
pt-osc工具应用模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| pt-online-schema-change \
--host="127.0.0.1" \
--port=3358 \
--user="root" \
--password="root@root" \
--charset="utf8" \
--max-lag=10 \
--check-slave-lag='xx.xx.xx.xx' \
--recursion-method="hosts" \
--check-interval=2 \
--datebase="testdb1" \
t="tb001" \
--alter="add column c4 int"
--execute
# 重点参数解释说明:
--execute:表示执行参数
--dr y-run:表示只进行模拟测试
其中表名只能使用参数t来设置,没有长参数;
|
pt-osc工具应用实践:
在下表结构中添加新的表结构字段信息;
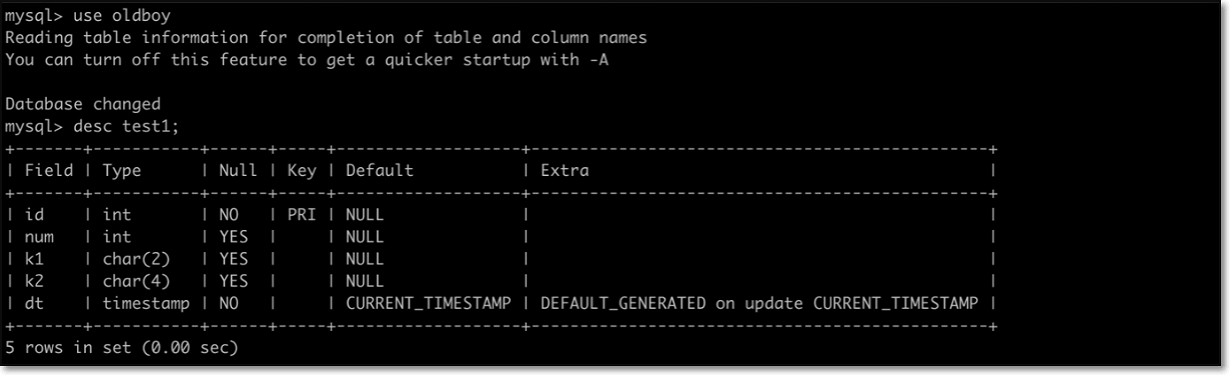
具体操作语句及语句参考:
1
2
3
4
5
6
7
8
| # 操作语句参考
pt-online-schema-change --user=xiaoQ --password=123 --host=10.0.0.51 --alter "add column state int not null default 1" D=test,t=t100w --print --execute
pt-online-schema-change --user=xiaoQ --password=123 --host=10.0.0.51 --alter "add index idx(num)" D=test,t=t100w --print --execute
# 实际操作语句
pt-online-schema-change --user=root --password=123 --host=192.168.30.101 --port=3307 --alter "add column state int not null default 1" D=oldboy,t=test1 --print -
-dr y-run
pt-online-schema-change --user=root --password=123 --host=192.168.30.101 --port=3307 --alter "add column state int not null default 1" D=oldboy,t=test1 --print -
-execute
|
说明:pt-osc工具bug汇总参考:https://cloud.tencent.com/developer/article/1821985
1.20.3 数据库服务工具实践-pt-table-checksum#
pt-table-checksum工具主要用于校验主从数据一致性情况,主要针对数据库或者数据表进行一致性检查;
此工具可以在主从复制时,当SQL线程出现异常报错时,可以利用此工具进行校验检查;
pt-table-checksum工具应用实践:
确认现有主从复制情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| # 查看主库节点情况:
[root@master ~]# mysql -S /data/3307/mysql.sock
mysql> select @@port;
+-----------+
| @@port |
+-----------+
| 3307 |
+-----------+
1 row in set (0.00 sec)
# 查看从库节点情况:
[root@master ~]# mysql -S /data/3309/mysql.sock
mysql> select @@port;
+-----------+
| @@port |
+-----------+
| 3309 |
+-----------+
1 row in set (0.00 sec)
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
-- 核实主从关系处于正常状态
|
主库节点创建校验库和校验用户信息:
1
2
3
4
5
6
7
| # 创建校验使用数据库信息
mysql> create database pt character set utf8;
-- 用于存储pt工具验证主从一致性信息,数据库中的表会自动创建;
# 创建校验使用连接用户信息
mysql> create user checksum@'192.168.30.%' identified with mysql_native_password by 'checksum';
mysql> grant all on *.* to checksum@'192.168.30.%';
mysql> flush privileges;
|
从库节点设置report报告信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| # 从库设置报告信息
[root@master ~]# vim /data/3309/my.cnf
[mysqld]
report_host='192.168.30.101'
report_port='3309'
-- 进行配置后需要重启数据库服务
mysql> select @@report_host;
+----------------+
| @@report_host |
+----------------+
| 192.168.30.101 |
+----------------+
1 row in set (0.00 sec)
mysql> select @@report_port;
+---------------+
| @@report_port |
+---------------+
| 3309 |
+---------------+
1 row in set (0.00 sec)
-- 验证从库是否设置成功
# 主库查看报告信息
mysql> show slave hosts;
+-----------+----------------+------+-----------+--------------------------------------+
| Server_id | Host | Port | Master_id | Slave_UUID |
+-----------+----------------+------+-----------+--------------------------------------+
| 9 | 192.168.30.101 | 3309 | 7 | 6dedf963-9e04-11ed-996f-000c2996c4f5 |
+-----------+----------------+------+-----------+--------------------------------------+
1 row in set, 1 warning (0.00 sec)
|
pt-table-checksum命令检验过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| # 模拟主从数据不一致
mysql> select * from test.t1;
+----+------+
| id | k1 |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
-- 主库数据信息情况
mysql> select * from test.t1;
+----+------+
| id | k1 |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
+----+------+
4 rows in set (0.00 sec)
-- 从库数据信息情况
# 验证主从一致性
[root@master ~]# pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=pt.checksums --create-replicate-table --databases=test --
tables=t1 h=192.168.30.101,P=3307,u=checksum,p=checksum
Checking if all tables can be checksummed ...
Starting checksum ...
TS ERRORS DIFFS ROWS DIFF_ROWS CHUNKS SKIPPED TIME TABLE
02-19T01:42:50 0 1 5 0 1 0 0.024 test.t1
-- 根据以上校验结果发现有一行差异情况
[root@master ~]# pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=pt.checksums --create-replicate-table --databases=test
h=192.168.30.101,P=3307,u=checksum,p=checksum
-- 表示可以针对库进行检查,但是对应库中表需要有主键或唯一键索引信息
# 执行参数信息说明
--[no]check-replication-filters:表示是否检查复制的过滤器,默认是yes,建议启用不检查模式;
--database | -d:指定需要被检查的数据库,多个库之间可以用逗号分隔;
--[no]-check-binlog-format:是否检查binlog文件的格式,默认是yes,建议开启不检查,因为在默认row格式下会出错;
--replicate:把checksum的信息写入到指定表中;
--replicate-check-only:只显示不同步信息
|
pt-table-checksum命令检验脚本:
1
2
3
4
5
| #!/bin/bash
date >>/root/db/checksum.log
pt-table-checksum --nocheck-binlog-format --nocheck-plan --nocheck-replication-filters --replicate=pt.checksums --set-vars innodb_lock_wait_timeout=120 --
databases test --tables t1 -u 'checksum' -p 'checksum' -h'192.168.30.101' >>/root/db/checksum.log
date >>/root/db/checksum.log
|
1.20.4 数据库服务工具实践-pt-table-sync#
pt-table-sync工具可以对主从不一致的数据信息,进行同步复制修复,实现恢复主从数据的一致性;
pt-table-sync工具应用实践:
工具应用实践:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 根据校验结果进行主从修复
pt-table-sync --replicate=pt.checksums --databases test --tables t1 h=192.168.30.101,u=checksum,p=checksum,P=3306
h=192.168.30.102,u=checksum,p=checksum,P=3306 --print
pt-table-sync --replicate=pt.checksums --databases test --tables t1 h=192.168.30.101,u=checksum,p=checksum,P=3306
h=192.168.30.102,u=checksum,p=checksum,P=3306 --execute
# 参数信息解释说明
--replicate:指定通过pt-table-checksum得到的表;
--database:指定执行同步的数据库
--tables:指定执行同步的表,多个表用逗号分隔;
--sync-to-master:指定一个DSN,即从库的IP,会通过show processlist或show slave status去自动的找主
h=:服务器地址,命令里有2个IP,第一次出现的是master的地址,第二次出现是slave的地址
u=:账号信息
p=:密码信息
--print:打印输出,但不执行命令
--execute:执行命令
# 根据校验结果进行主从修复(真实操作)
pt-table-sync --replicate=pt.checksums --databases test --tables t1 h=192.168.30.101,u=checksum,p=checksum,P=3307
h=192.168.30.101,u=checksum,p=checksum,P=3309 --print
pt-table-sync --replicate=pt.checksums --databases test --tables t1 h=192.168.30.101,u=checksum,p=checksum,P=3307
h=192.168.30.101,u=checksum,p=checksum,P=3309 --execute
|
1.20.5 数据库服务工具实践-pt-duplicate-key-checker#
pt-duplicate-key-checker工具主要用于检查数据库重复索引信息;
pt-duplicate-key-checker工具实践应用:
1
| pt-duplicate-key-checker --database=test --host=10.0.0.51 --user=root --password=123 --port=3307
|
1.20.6 数据库服务工具实践-pt-kill#
pt-kill工具主要用于杀掉异常的数据库连接会话信息;
pt-kill工具实践操作应用:
实践情况-01:杀掉空闲链接sleep 5秒的SQL,并把日志放在/home/pt-kill.log文件中
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --match-command sleep --idle-time 5 --victim all --interval 5 --kill --daemonize -S /tmp/mysql.sock --
pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log &
|
实践情况-02:查询select 语句超过1分钟的会话
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --busy-time 60 --match-info "select|SELECT" --victim all --interval 5 --kill --daemonize -S /tmp/mysql.sock --
pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log &
|
实践情况-03:kill掉查询语句 select ..ifnull.* 语句开头的SQL
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --victim all --busy-time=0 --match-info "select IFNULL.*" --interval 1 -S /tmp/mysql.sock --kill --daemonize --
pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log &
|
实践情况-04:kill掉state locked
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --victim all --match-state="Locked" --interval 5 --kill --daemonize -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print -
-log=/tmp/pt-kill.log &
|
实践情况-05:kill掉 A库 web为10.0.0.11的连接
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --victim all --match-db="a" --match-host='10.0.0.11' --kill --daemonize --interval 10 -S /tmp/mysql.sock --
pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log &
|
实践情况-06:指定哪个用户kill
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --victims all --match-user="root" --kill --daemonize --interval 10 -S /tmp/mysql.sock --pid=/tmp/ptkill.pid --print --
log=/tmp/pt-kill.log &
|
实际情况-07:kill掉 command query|Execute
1
2
| /usr/bin/pt-kill --user=用户名 --password=密码 --victims all --match-command="query|Execute" --interval 10 --kill --daemonize -S /tmp/mysql.sock --
pid=/tmp/ptkill.pid --print --log=/tmp/pt-kill.log &
|
pt-kill应用参数信息参考:
1
2
3
4
5
6
7
8
9
10
11
12
13
| # 常用参数解释说明
--daemonize:放在后台以守护进程的形式运行;
--interval:多久运行一次,单位时间可以是s,m,h,d;默认是s,参数不设置默认是5秒;
--victims:默认是oldest,只杀最古老的查询。这是防止被查杀是不是真的长时间运行的查询,只是长期等待,这种匹配按时间查询,杀死一个时间最高值
--all:杀掉所有满足的线程
--kill-query:只杀掉连接执行的语句,但是线程不会被终止
--print:打印满足条件的语句
--busy-time:批次查询已运行的时间超过这个时间的线程
--idle-time:杀掉sleep空闲了多少时间的连接线程,必须在--match-command sleep时才有效-也就是匹配使用
--match-command:匹配相关的语句
--ignore-command:忽略相关的匹配,这两个搭配使用一定是ignore-command在前,match-command在后
--match-db cdelzone:匹配哪个库
command:有Quer y、sleep、Binlog Dump、Connect、Delayed insert、Execute、Fetch、Init DB、kill、Prepare、Processlist、Quit、Reset stmt、Table Dump
|
1.20.7 数据库服务工具实践-pt-slave-find#
pt-slave-find工具主要用于输出主从关系的拓扑结构信息;
pt-slave-find工具应用实践:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| [root@master local]# pt-slave-find -h192.168.30.101 -P3307 -uchecksum -pchecksum
192.168.30.101:3307
Version 8.0.26
Server ID 7
Uptime 16:16:43 (started 2023-02-18T11:12:42)
Replication Is not a slave, has 1 slaves connected, is not read_only
Filters
Binar y logging ROW
Slave status
Slave mode STRICT
Auto-increment increment 1, offset 1
InnoDB version 8.0.26
+- 192.168.30.101:3309
Version 8.0.26
Server ID 9
Uptime 01:59:10 (started 2023-02-19T01:30:15)
Replication Is a slave, has 0 slaves connected, is not read_only
Filters
Binar y logging ROW
Slave status 0 seconds behind, running, no errors
Slave mode STRICT
Auto-increment increment 1, offset 1
InnoDB version 8.0.26
|
1.20.8 数据库服务工具实践-pt-heartbeat#
pt-heartbeat工具主要用于监控主从延时的情况;
pt-heartbeat工具应用实践:
1
2
3
4
5
6
7
| # 主库进行操作
pt-heartbeat --user=root --ask-pass --host=192.168.30.101 --port=3307 --create-table -D test --interval=1 --update --replace --daemonize
--
# 从库进行操作
pt-heartbeat --user=root --ask-pass --host=192.168.30.101 --port=3309 -D test --table=heartbeat --monitor
pt-heartbeat --user=root --password=123 --host=192.168.30.101 --port=3309 -D test --table=heartbeat --monitor --file=/tmp/aa.log &
-- 可以模拟停止从库SQL线程(stop slave sql_thread;),查看延时情况
|
1.20.9 数据库服务工具实践-pt-show-grants#
pt-show-grants工具主要用于权限信息迁移,当只迁移业务数据库信息时,可以实现单独迁移用户和授权信息;
pt-show-grants工具实践应用:(导出数据库用户权限信息)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| [root@master local]# pt-show-grants -h192.168.30.101 -P3307 -uchecksum -pchecksum
-- Grants dumped by pt-show-grants
-- Dumped from server 192.168.30.101 via TCP/IP, MySQL 8.0.26 at 2023-02-19 03:54:22
-- Grants for 'checksum'@'192.168.30.%'
CREATE USER IF NOT EXISTS 'checksum'@'192.168.30.%';
ALTER USER 'checksum'@'192.168.30.%' IDENTIFIED WITH 'mysql_native_password' AS '*E5E390AF1BDF241B51D9C0DBBEA262CC9407A2DF' REQUIRE NONE
PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROLE, CREATE ROUTINE, CREATE TABLESPACE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE,
DROP, DROP ROLE, EVENT, EXECUTE, FILE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW
DATABASES, SHOW VIEW, SHUTDOWN, SUPER, TRIGGER, UPDATE ON *.* TO `checksum`@`192.168.30.%`;
GRANT
APPLICATION_PASSWORD_ADMIN,AUDIT_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_
ADMIN,FLUSH_OPTIMIZER_COSTS,FLUSH_STATUS,FLUSH_TABLES,FLUSH_USER_RESOURCES,GROUP_REPLICATION_ADMIN,INNODB_REDO_LOG_ARCHIVE,INNODB_RED
O_LOG_ENABLE,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMI
N,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,X
A_RECOVER_ADMIN ON *.* TO `checksum`@`192.168.30.%`;
-- Grants for 'mysql.infoschema'@'localhost'
CREATE USER IF NOT EXISTS 'mysql.infoschema'@'localhost';
ALTER USER 'mysql.infoschema'@'localhost' IDENTIFIED WITH 'caching_sha2_password' AS
'$A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT LOCK PASSWORD
HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT SELECT ON *.* TO `mysql.infoschema`@`localhost`;
GRANT SYSTEM_USER ON *.* TO `mysql.infoschema`@`localhost`;
-- Grants for 'mysql.session'@'localhost'
CREATE USER IF NOT EXISTS 'mysql.session'@'localhost';
ALTER USER 'mysql.session'@'localhost' IDENTIFIED WITH 'caching_sha2_password' AS
'$A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT LOCK PASSWORD
HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT BACKUP_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,PERSIST_RO_VARIABLES_ADMIN,SESSION_VARIABLES_ADMIN,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN
ON *.* TO `mysql.session`@`localhost`;
GRANT SELECT ON `mysql`.`user` TO `mysql.session`@`localhost`;
GRANT SELECT ON `performance_schema`.* TO `mysql.session`@`localhost`;
GRANT SHUTDOWN, SUPER ON *.* TO `mysql.session`@`localhost`;
-- Grants for 'mysql.sys'@'localhost'
CREATE USER IF NOT EXISTS 'mysql.sys'@'localhost';
ALTER USER 'mysql.sys'@'localhost' IDENTIFIED WITH 'caching_sha2_password' AS
'$A$005$THISISACOMBINATIONOFINVALIDSALTANDPASSWORDTHATMUSTNEVERBRBEUSED' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT LOCK PASSWORD
HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT SELECT ON `sys`.`sys_config` TO `mysql.sys`@`localhost`;
GRANT SYSTEM_USER ON *.* TO `mysql.sys`@`localhost`;
GRANT TRIGGER ON `sys`.* TO `mysql.sys`@`localhost`;
GRANT USAGE ON *.* TO `mysql.sys`@`localhost`;
-- Grants for 'repl'@'192.168.30.%'
CREATE USER IF NOT EXISTS 'repl'@'192.168.30.%';
ALTER USER 'repl'@'192.168.30.%' IDENTIFIED WITH 'mysql_native_password' AS '*23AE809DDACAF96AF0FD78ED04B6A265E05AA257' REQUIRE NONE PASSWORD
EXPIRE DEFAULT ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT REPLICATION SLAVE ON *.* TO `repl`@`192.168.30.%`;
-- Grants for 'root'@'192.168.30.%'
CREATE USER IF NOT EXISTS 'root'@'192.168.30.%';
ALTER USER 'root'@'192.168.30.%' IDENTIFIED WITH 'mysql_native_password' AS '*23AE809DDACAF96AF0FD78ED04B6A265E05AA257' REQUIRE NONE PASSWORD
EXPIRE DEFAULT ACCOUNT UNLOCK PASSWORD HISTORY DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROLE, CREATE ROUTINE, CREATE TABLESPACE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE,
DROP, DROP ROLE, EVENT, EXECUTE, FILE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW
DATABASES, SHOW VIEW, SHUTDOWN, SUPER, TRIGGER, UPDATE ON *.* TO `root`@`192.168.30.%`;
GRANT
APPLICATION_PASSWORD_ADMIN,AUDIT_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_
ADMIN,FLUSH_OPTIMIZER_COSTS,FLUSH_STATUS,FLUSH_TABLES,FLUSH_USER_RESOURCES,GROUP_REPLICATION_ADMIN,INNODB_REDO_LOG_ARCHIVE,INNODB_RED
O_LOG_ENABLE,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMI
N,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,X
A_RECOVER_ADMIN ON *.* TO `root`@`192.168.30.%`;
-- Grants for 'root'@'localhost'
CREATE USER IF NOT EXISTS 'root'@'localhost';
ALTER USER 'root'@'localhost' IDENTIFIED WITH 'caching_sha2_password' REQUIRE NONE PASSWORD EXPIRE DEFAULT ACCOUNT UNLOCK PASSWORD HISTORY
DEFAULT PASSWORD REUSE INTERVAL DEFAULT PASSWORD REQUIRE CURRENT DEFAULT;
GRANT ALTER, ALTER ROUTINE, CREATE, CREATE ROLE, CREATE ROUTINE, CREATE TABLESPACE, CREATE TEMPORARY TABLES, CREATE USER, CREATE VIEW, DELETE,
DROP, DROP ROLE, EVENT, EXECUTE, FILE, INDEX, INSERT, LOCK TABLES, PROCESS, REFERENCES, RELOAD, REPLICATION CLIENT, REPLICATION SLAVE, SELECT, SHOW
DATABASES, SHOW VIEW, SHUTDOWN, SUPER, TRIGGER, UPDATE ON *.* TO `root`@`localhost` WITH GRANT OPTION;
GRANT
APPLICATION_PASSWORD_ADMIN,AUDIT_ADMIN,BACKUP_ADMIN,BINLOG_ADMIN,BINLOG_ENCRYPTION_ADMIN,CLONE_ADMIN,CONNECTION_ADMIN,ENCRYPTION_KEY_
ADMIN,FLUSH_OPTIMIZER_COSTS,FLUSH_STATUS,FLUSH_TABLES,FLUSH_USER_RESOURCES,GROUP_REPLICATION_ADMIN,INNODB_REDO_LOG_ARCHIVE,INNODB_RED
O_LOG_ENABLE,PERSIST_RO_VARIABLES_ADMIN,REPLICATION_APPLIER,REPLICATION_SLAVE_ADMIN,RESOURCE_GROUP_ADMIN,RESOURCE_GROUP_USER,ROLE_ADMI
N,SERVICE_CONNECTION_ADMIN,SESSION_VARIABLES_ADMIN,SET_USER_ID,SHOW_ROUTINE,SYSTEM_USER,SYSTEM_VARIABLES_ADMIN,TABLE_ENCRYPTION_ADMIN,X
A_RECOVER_ADMIN ON *.* TO `root`@`localhost` WITH GRANT OPTION;
GRANT PROXY ON ''@'' TO 'root'@'localhost' WITH GRANT OPTION;
|
说明:其他工具命令自学推荐:pt-query-digest(分析执行计划)、pt-summary(数据库信息总览);