基础章节-01-MySQL数据库服务中级课程

1.00 课程知识章节说明
目前在互联网的实际应用中,各个企业都会比较关注自身网站的数据信息,既要保证数据信息的安全性,同时也要保证数据存储读取效率
并且在特殊的场景下,还要对存储的数据信息进行检索和分析;因此数据库服务业务已经在各行各业应用非常的广泛
对于互联网领域的技术人员,对于数据库服务知识的掌握,也将是在求职时必备的技能,有些时候还会绝对入职的定级和薪资水平。
1.07 数据库服务索引知识
1.7.1 数据库索引相关概念
索引概念介绍:
索引是数据库中用来提高数据读取性能的常用工具,所有mysql列类型都可以被索引,对相关列使用索引;
可以是提高select操作性能的最佳途径,可以尽可能快的锁定要查询数据的范围,从而达到加速查询的目的(减少IO消耗);
一般索引设置都是应用在比较大的数据表上,比如百万级别、千万级别或亿级别的数据表中,从而完成一些针对性优化;
可以简单理解:数据库索引相当于书的目录,可以借助索引有针对的查看相应数据的信息,避免了全盘检索带来的工作量;
主要利用MySQL中的索引,可以快速锁定查询范围,mysql索引比较适合范围查找数据;
1.7.2 数据库索引类型介绍
在MySQL数据库服务中,是有很多种索引类型的,但是比较常用的索引类型主要有:
| 序号 | 类型 | 说明 |
|---|---|---|
| 类型01 | B + Tree | 默认类型索引 |
| 类型02 | Hash | 算法类型索引 |
| 类型03 | R + Tree | 空间类型索引 |
| 类型04 | Fulltext | 全文类型索引 |
通过以上两种算法的介绍,了解到都存在一些缺陷或问题,因此数据库在检索数据信息时,最终采用的算法是B+Tree,其中的B表示平衡
并且BTREE还可以细分为B-tree或B+tree,以及B++tree,其中的加号就是表示增强版或优化版的BTree;
在讲解B+树之前先了解一下树的整体结构,无非就是二叉树、二叉搜索树、平衡二叉树,更高级一点的有红黑树、Btree、B+tree等;
而树的查找性能取决于树的高度,让树尽可能平衡是为了降低树的高度。
为什么MySQL会选用B+树的结构,可以先来看看其他的树形结构:
二叉树:
二叉树的每一个节点都只有两个子节点,当需要向其插入更多的数据的时候,就必须要增加树的高度,而增加树的高度会导致IO消耗大;
对于二叉树而言,它的查找操作的时间复杂度就是树的高度,树的高度越高查询性能就会随着数据的增多越来越低。
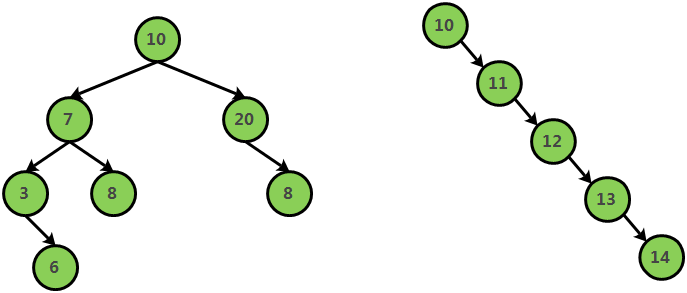
二叉树节点中,还存在非正常的倾斜(比如ID自增的情况)的二叉树,查询一次数据就相当于全表搜索,因此二叉树的查询性能特别差
红黑树:
红黑树一种平衡二叉树,它复杂的定义和规则都是为了保证树的平衡性;
对于B++tree算法的底层算法逻辑理解:
利用Btree算法还是快速锁定100个盒子中,有代金券的盒子编号,如下图所示:
将需要存储的数据信息,均匀分配保存到对应页当中,最终数据信息的均匀存储(落盘)
根据页节点存储的数据信息,取出页节节点最小数据信息,并将每个叶节点最小数据信息进行汇总整合,生成相应内部节点数据;
实质上存储的是下层页节点的区间范围,以及与之对应的指针信息,最后构建出内部节点信息;
根据内部节点存储的数据信息,取出内部节点最小数据信息,并将每个内部节点最小值信息进行汇总整合,生成相应根节点数据;
根节点只能有占用一个页区域,如果一个页区域空间不够,需要进行内部节点层次扩展,但是尽量要保证层次越少越好;
实质上存储的是下层内部节点的区域范围,以及与之对应的指针信息,最后构建出独立且唯一的根节点信息;
整个树形结构,越向上节点存储数据的范围越大,然后依次再分发数据到下面的小范围,最终形成多叉树;
由于出现了多叉树,就表示全部数据分布在多个链表上,避免了单条链表存储数据,同时可以实现并发的访问数据
对于加号表示增强,其中增强表示在整个链表上,增加了同级相邻节点之间的双向指针,从而实现相邻节点相互跳转
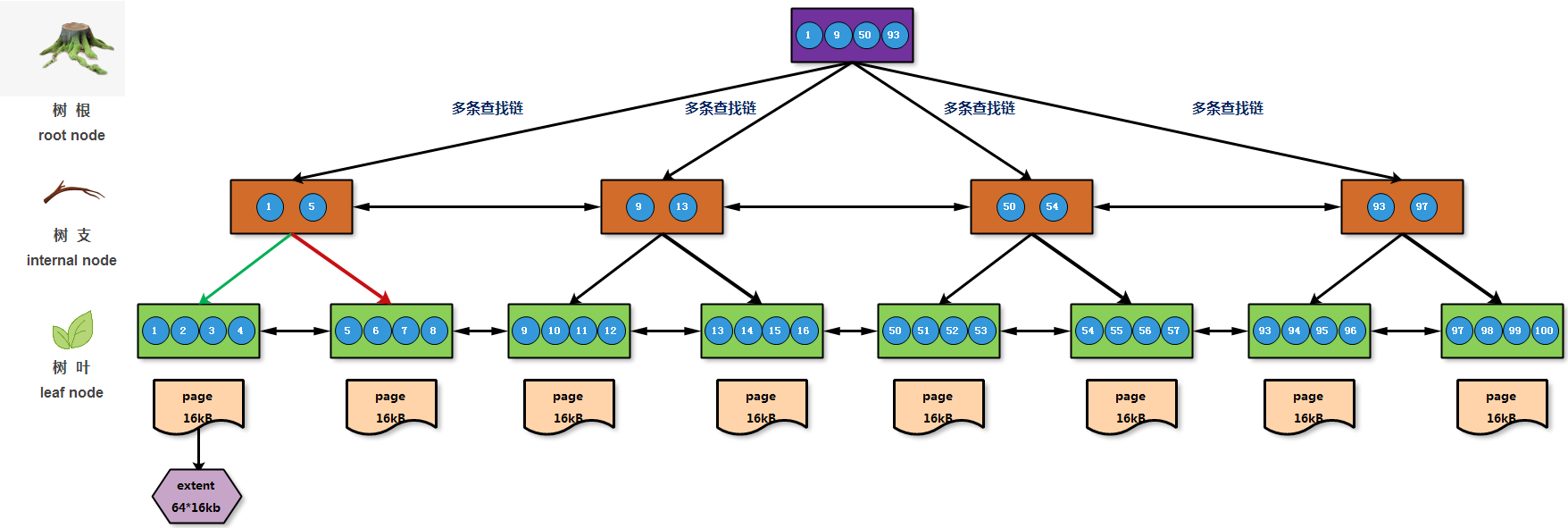
根据以上B+Tree的结构说明,假设现在需要查找54这个数据值信息所在的数据页:等值查询
根据定义查找的数值信息,首先在根节点中获取数值所在的区间范围和相应指针信息,从而找到下层对应的内部节点信息;
根据定义查找的数据信息,其次在枝节点中获取数值所在的区域范围和相应指针信息,从而找到下层对应的叶子节点信息;
根据定义查找的数据信息,最后在叶子节点中获取最终的数据信息,结果结合上图经历三步完成了数据查找(3*16=48kB);
在利用BTree查找数据信息时,会结合树形层次结构,来决定查询数据的步骤过程,并且理论上每个数据查找过程步骤相同;
总结:B代表的平衡含义就是,每次查找数据消耗的IO数量是一致的,并且读取的页数量也是一致的,查找时间复杂度是一致的;
根据以上B+Tree的结构说明,假设现在需要查找大于90这个数据值信息所在的数据页:不等值查询
根据定义查找的数值信息,首先在根节点中获取首个大于指定数值的区间范围和相应指针信息,从而找到下层对应的内部节点信息;
根据定义查找的数据信息,其次在枝节点中获取数值所在的区域范围和相应指针信息,并且结合双向指针进行预读;
根据定义查找的数据信息,最后在叶子节点中获取最终的数据信息,并且结合双向指针进行预读,查询其余大于90的数值;
在利用BTree查找数据信息时,由于存在双向指针概念,可以避免重复从根查找问题,减少IO消耗,结合预读快速调取数据到内存中
总结:在BTree中的双向链接增强特性和预读功能,可以根据簇(64page)读取数据,可以使数据信息的范围查找变得更加方便高效
1.7.3 数据库索引构建过程
数据库服务在进行BTree索引构建时,是比较重要的知识点,因为最终还是会应用BTree算法知识进行索引的构建,常用方法有:
索引方式一:聚簇索引(集群索引/聚集索引)
聚簇索引主要是:将多个簇(区-64个数据页-1M)聚集在一起就构成了所谓聚簇索引,也可以称之为主键索引;
聚簇索引作用是:用来组织存储表的数据行信息的,也可以理解为数据行信息都是按照聚簇索引结构进行存储的,即按区分配空间的;
聚簇索引的存储:聚簇是多个簇,簇是多个连续数据页(64个),页是多个连续数据块(4个),块是多个连续扇区(8个);
总结:利用聚簇索引可以实现从物理上或逻辑上,都能满足数据存储的连续性关系,方便进行数据查找的有序性IO;(IOT组织表)
聚簇索引的构建方式:
数据表创建时,显示的构建了主键信息(pk),主键(pk)就是聚簇索引;
数据表创建时,没有显示的构建主键信息时,会将第一个不为空的UK的列做为聚簇索引;
数据表创建时,以上条件都不符合时,生成一个6字节的隐藏列作为聚簇索引;
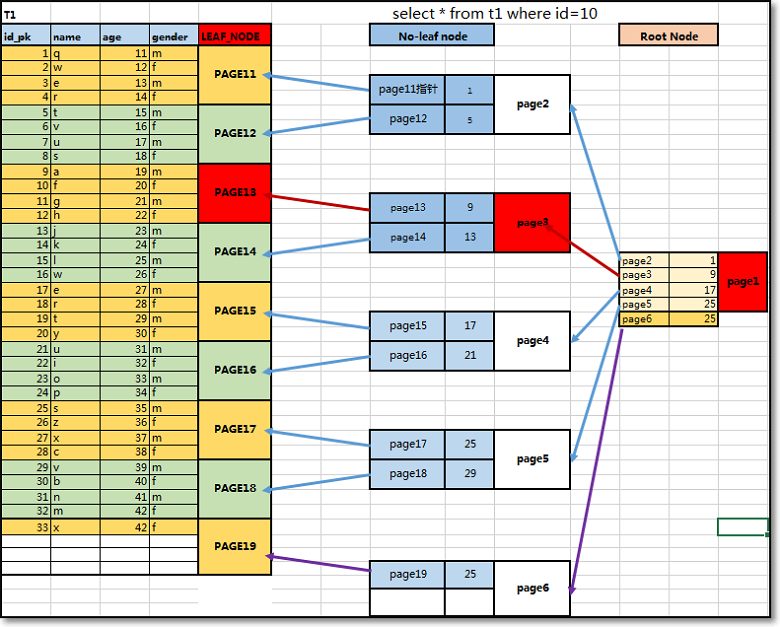
结合下图信息,可以看出聚簇索引组织存储数据过程与加速查询过程原理:
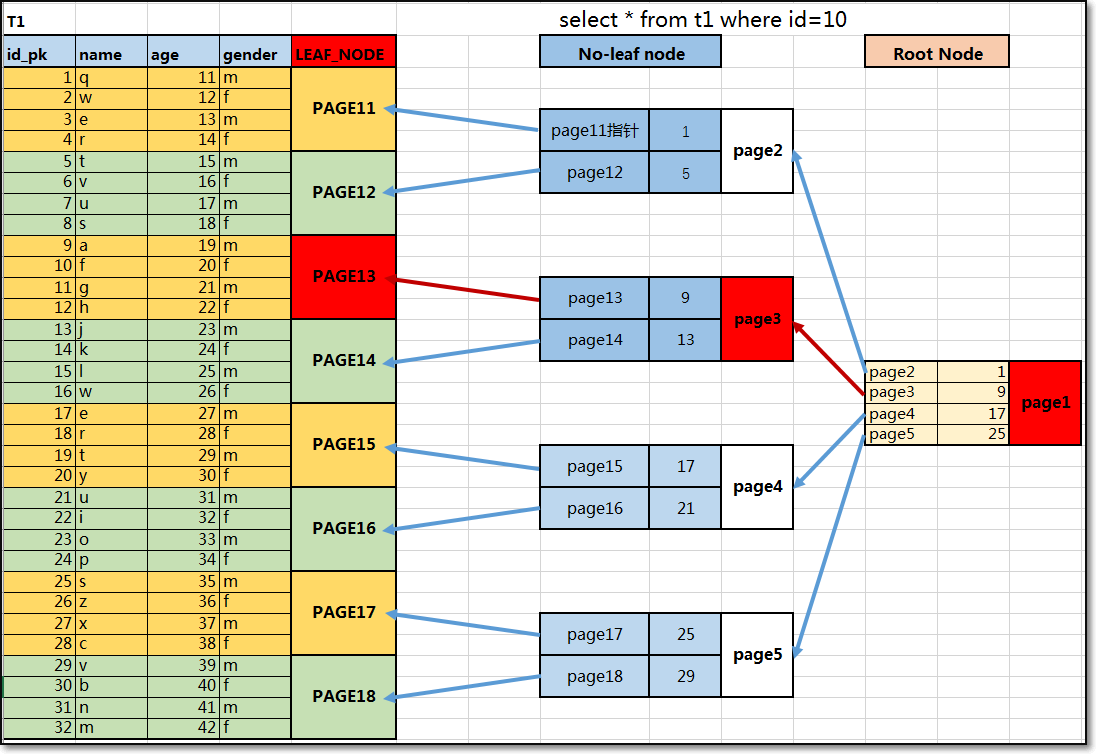
以上图信息为例,若显示创建ID列为pk自增列:
① 按照ID逻辑顺序,在同一个区中连续的数据页上,有序存储数据行;
② 数据行所在的数据页,作为聚簇索引的叶子节点(叶子节点就是所有数据行);
③ 叶子节点构建完后,可以构建no-left(支节点),用于保存的是leaf节点中的ID范围和指针信息;
④ 支节点构建完后,可以构建root(根节点),用于保存的是no-leaf节点中的ID范围和指针信息;
⑤ 并且leaf节点和no-leaf相邻数据页之间都具有双向指针,从而加速数据的范围查找;
索引方式二:辅助索引
辅助索引主要是:主要用于辅助聚簇索引查询的索引,一般按照业务查找条件,建立合理的索引信息,也可以称之为一般索引;
辅助索引作用是:主要是将需要查询的列信息可以和聚合索引信息建立有效的关联,从而使数据查询过程更高效,节省IO和CPU消耗
辅助索引的存储:调取需要建立的辅助索引列信息,并加上相应主键列的所有信息,存储在特定的数据页中;
总结:利用辅助索引与聚合索引建立的关联,先经过辅助索引的查询获取对应聚簇索引,在经过聚簇索引回表查询获取详细数据;
辅助索引的构建方式:
数据表创建时,显示的构建了一般索引信息(mul),一般索引信息(mul)就是辅助索引;
数据表创建时,没有显示的构建一般索引信息时,在查询检索指定数据信息,会进行全表扫描查找数据;
结合下图信息,可以看出辅助索引组织存储数据过程与加速查询过程原理:
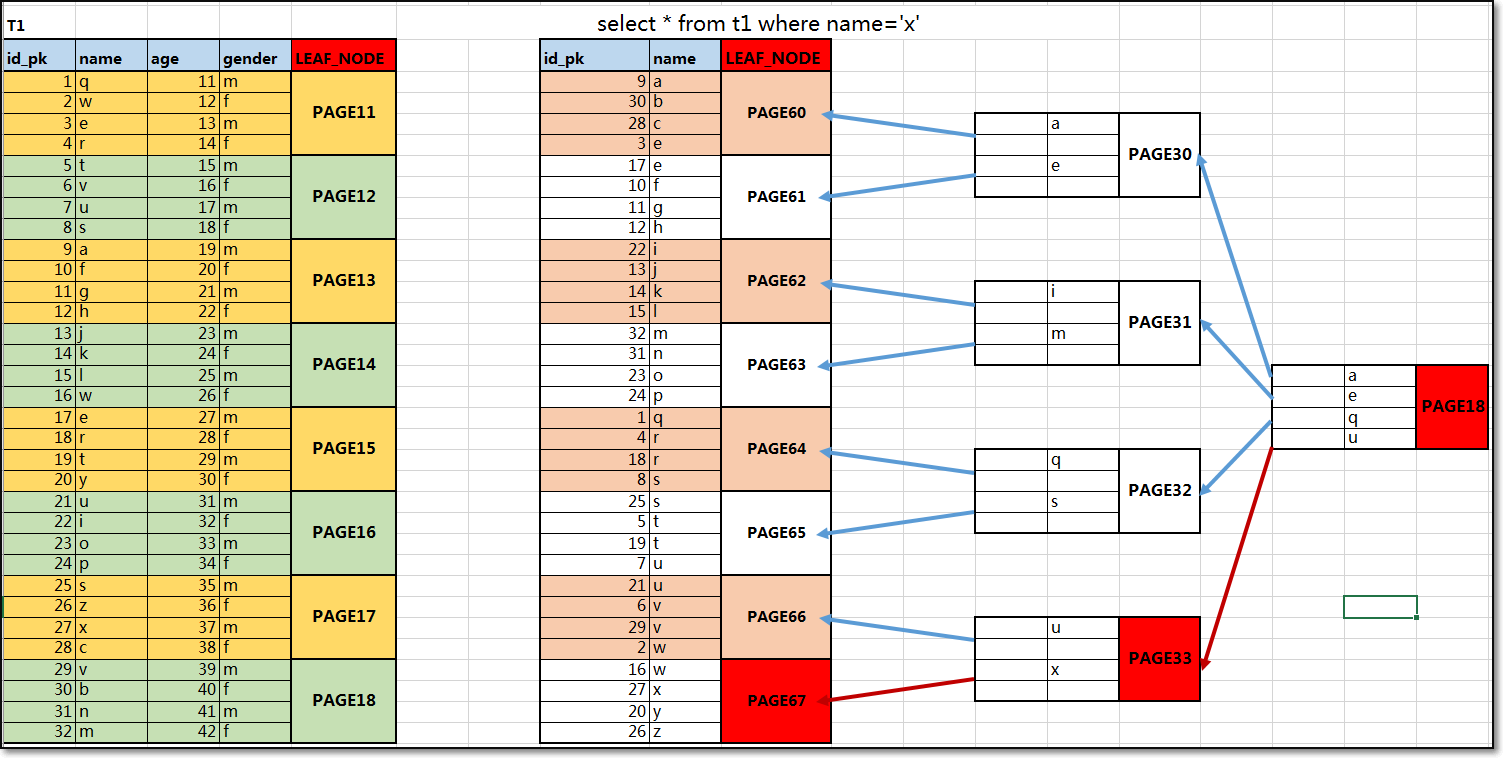
以上图信息为例,若显示创建name列为mul查询列:
① 调取需要建立的辅助索引列信息,并加上相应主键列的所有信息,存储在特定的内存区域中;
② 根据调取的辅助索引列信息,进行字符的顺序排序,便于形成范围查询的区间,并将排序后的数据信息存储在特定数据页中;
③ 叶子节点构建完后,可以构建no-left(支节点),用于保存的是leaf节点中的字符范围和指针信息;
④ 支节点构建完后,可以构建root(根节点),用于保存的是no-leaf节点中的字符范围和指针信息;
⑤ 找到相应辅助索引的数据信息后,在根据辅助索引与聚簇索引的对应关系,获取到相应的主键信息,从而获取相应其他数据信息
在利用聚簇索引获取其他数据信息的过程,也可以称之为回表查询过程;
辅助索引检索数据产生回表问题分析:(回表次数越少越高)
产生问题:
① 在回表过程中,有可能会出现多次的回表,从而造成磁盘IOPS的升高;(因为是随机IO操作过程)
② 在回表过程中,有可能会出现多次的回表,从而造成磁盘IO量的增加;
解决方法:
① 可以建立联合索引,调整查询条件,使辅助索引过滤出更精细主键ID信息,从而减少回表查询的次数;
② 可以控制查询信息,实现覆盖索引,辅助索引完全覆盖查询结果;
③ 优化器算法做调整???(MRR-多路读功能 ICP-索引下推功能 )
构建索引树高度问题分析:(索引树高度越低越好)
影响索引树高度因素:
① 数据行数量会对高度产生影响;(3层BTREE – 可以实现一般2000万行数据索引的存储-20~30列表)
解决方法:可以拆分表拆分库或者实现分布式存储;
② 索引字段长度过大会对高度产生影响;
解决方法:利用前缀索引解决问题
③ 数据类型设定会对高度产生影响;
解决方法:列定义时,选择简短合适的数据类型;
1.7.4 数据库索引应用方法
在进行索引操作之前,可以进行一个压力测试,将一个100W数据量的数据库备份数据进行备份恢复:
| |
数据库压力测试结果情况:

进行索引建立优化:
| |
在进行压测检查确认:
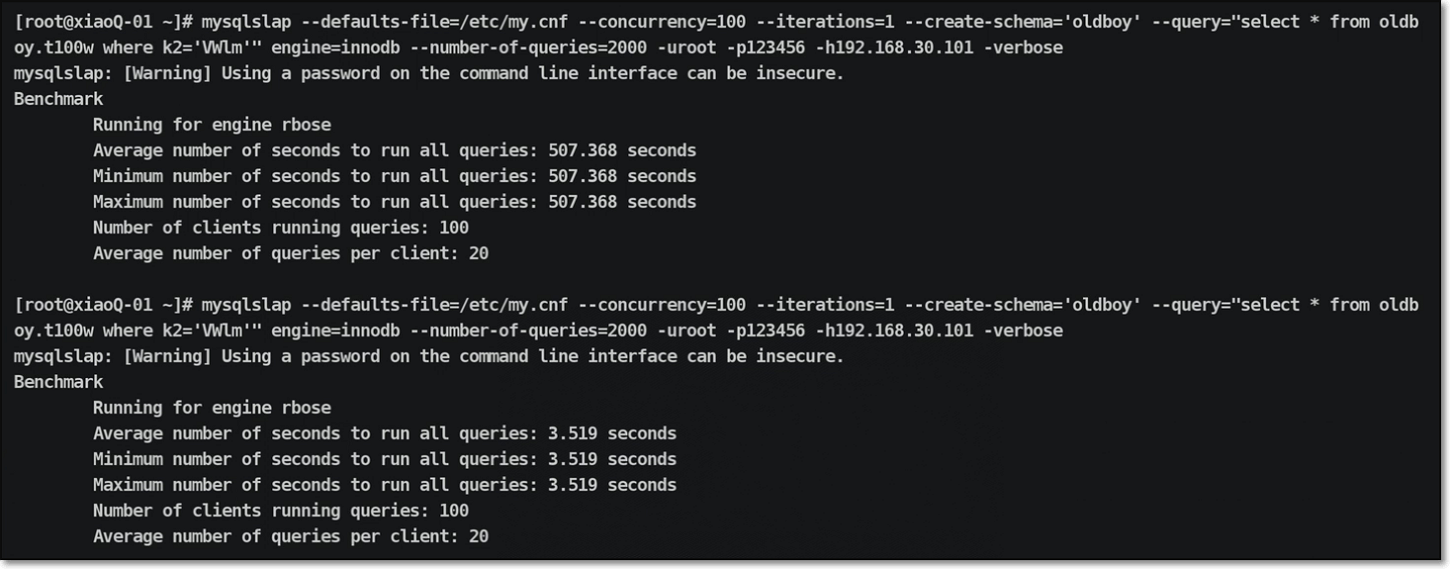
01 索引基本操作说明:
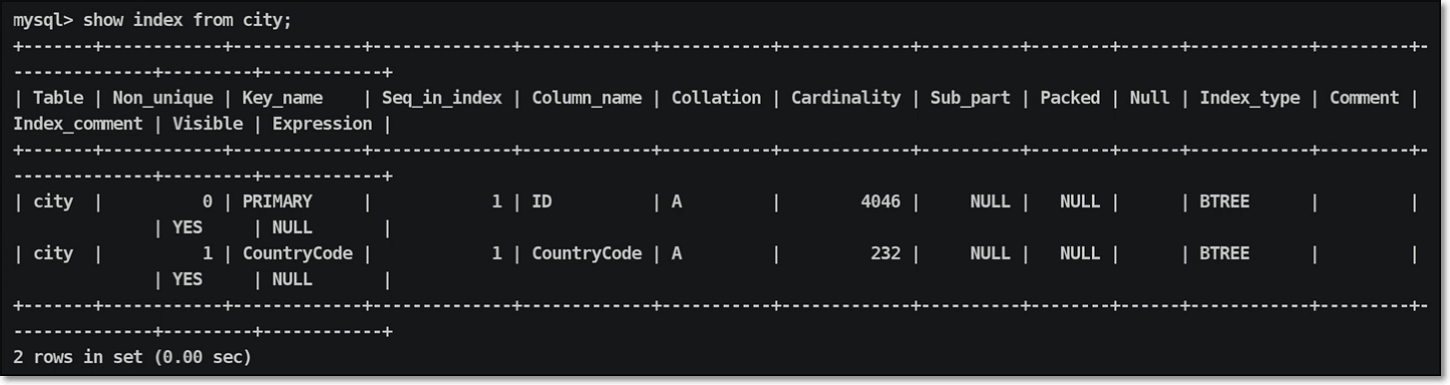
查询索引信息:
| |
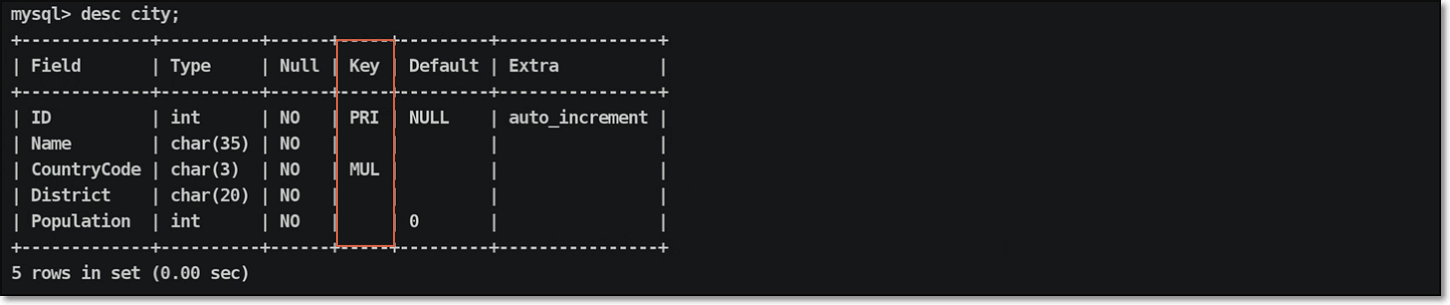
索引信息的展示形式:
| 序号 | 索引标识 | 解释说明 |
|---|---|---|
| 01 | PK ( PRI) | 表 ⽰为聚簇索引,也可以理解为主键索引 |
| 02 | K ( MUL) | 表 ⽰为辅助索引,也可以理解为一般索引 |
| 03 | UK | 表 ⽰唯一键索引 |
| |
创建索引信息:
创建单列索引方法:
| |
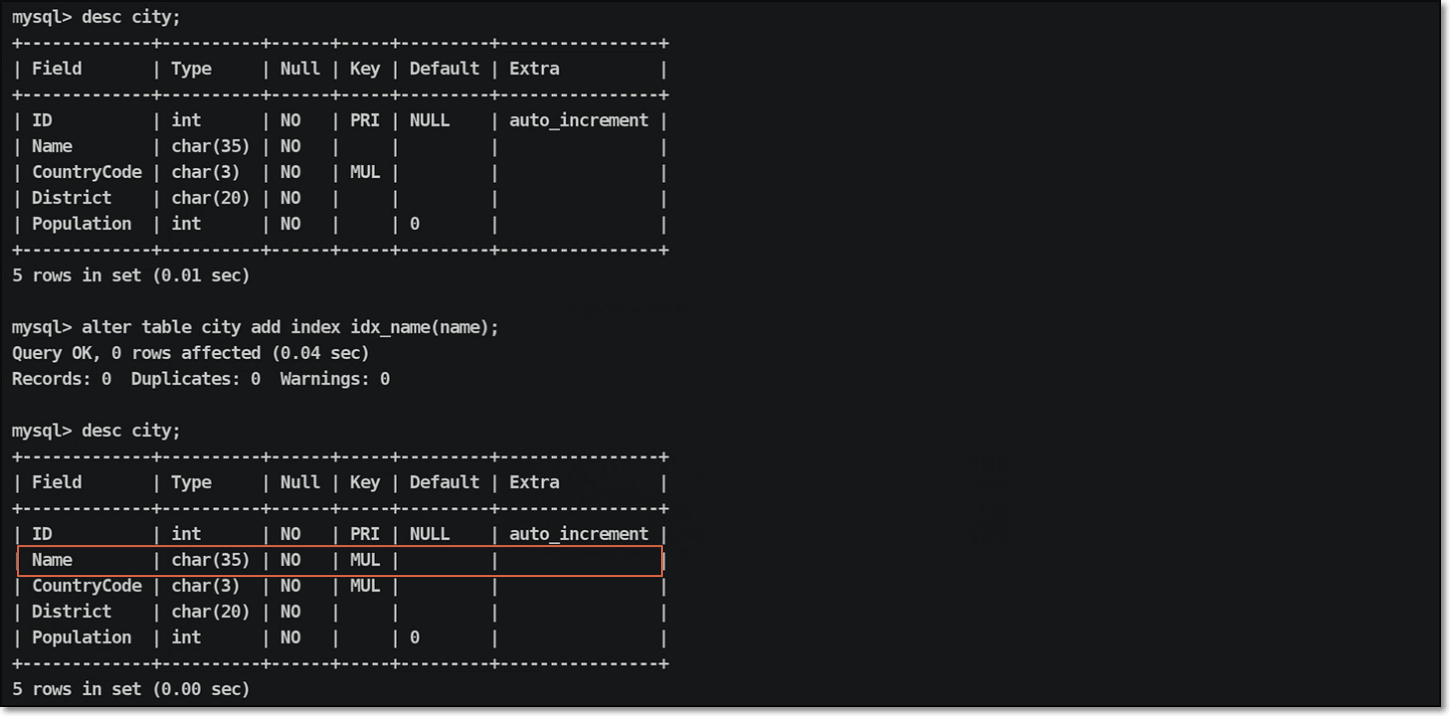
创建联合索引方法:
| |
创建前缀索引方法:
| |
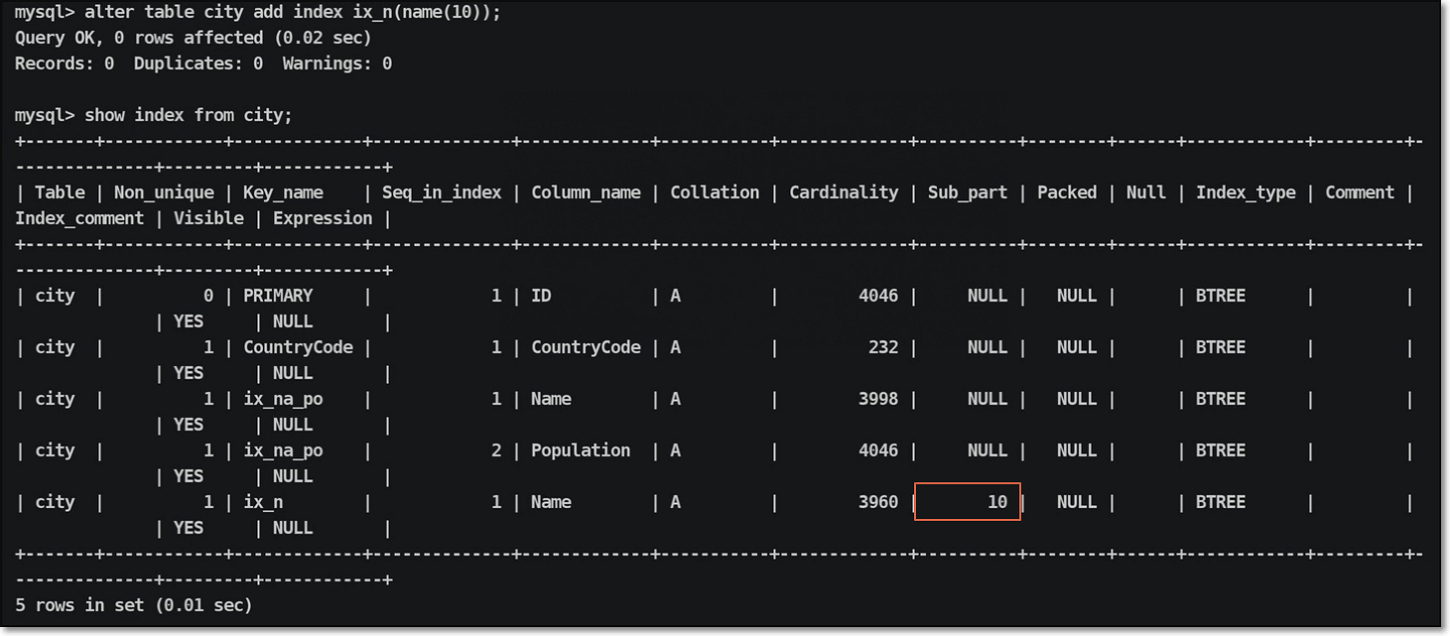
删除索引信息:
| |
1.08 数据库服务执行计划
1.8.1 数据库执行计划概念
执行计划介绍:
在介绍数据库服务程序运行逻辑时,在SQL层处理SQL语句时,会根据解析器生成解析树(多种处理方案);
然后在利用优化器生成最终的执行计划,然后在根据最优的执行计划进行执行SQL语句;
作为管理员,可以在某个语句执行前,将语句对应的执行计划提取出来进行分析,便可大体判断语句的执行行为,从而了解执行效果;
可以简单理解:执行计划就是最优的一种执行SQL语句的方案,表示相应SQL语句是如何完成的数据查询与过滤,以及获取;
1.8.2 数据库执行计划获取
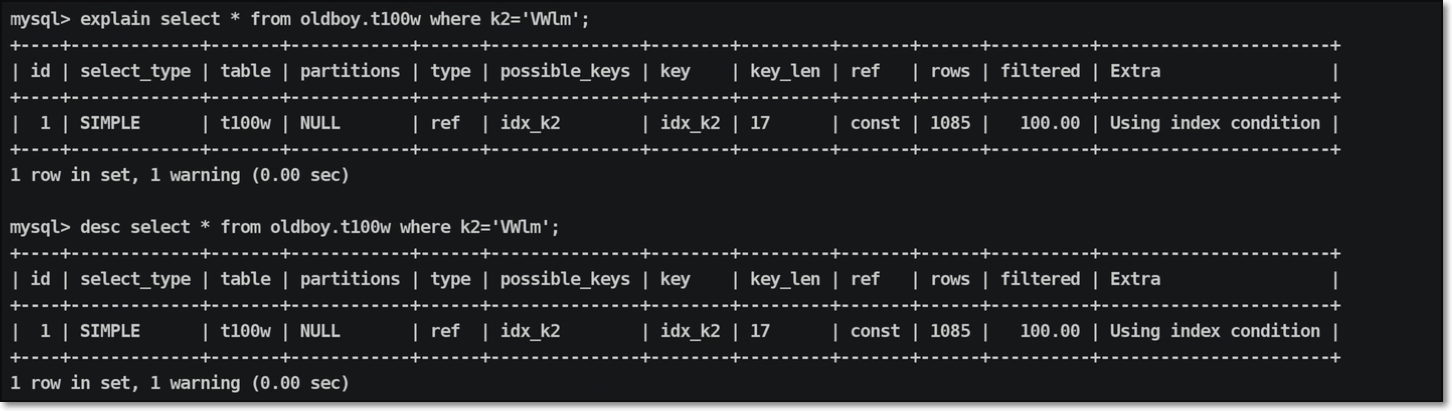
可以利用命令进行获取执行计划信息:explain/desc
| |
命令执行输出信息:
输出信息解释说明:
| 序号 | 字段 | 解释说明 |
|---|---|---|
| 01列 | ID | 表 ⽰语句执行顺序,单表查询就是一行执行计划,多表查询就会多行执行计划; |
| 02列 | select_type | 表 ⽰语句查询类型, sipmle 表 ⽰简单( 普通 )查询 |
| 03列 | table | 表 ⽰语句针对的表,单表查询就是一张表,多表查询显 ⽰多张表; |
| 05列 | type * * * | 表 ⽰索引应用类型,通过类型可以判断有没有用索引,其次判断有没有更好的使用索引 |
| 06列 | possible _ keys | 表 ⽰可能使用到的索引信息,因为列信息是可以属于多个索引的 |
| 07列 | key | 表 ⽰确认使用到的索引信息 |
| 08列 | key_ len * * * | 表 ⽰索引覆盖长度,对联合索引是否都应用做判断 |
| 10列 | rows | 表 ⽰查询扫描的数据行数(尽量越少越好),尽量和结果集行数匹配,从而使查询代价降低 |
| 11列 | fltered | 表 ⽰查询的匹配度 |
| 12列 | Extra * * * | 表 ⽰额外的情况或额外的信息 |
1.8.3 数据库索引应用类型
利用类型信息,来判断确认索引的扫描方式,常见的索引扫描方式类型:
| 序号 | 类型 | 解释说明 |
|---|---|---|
| 01 | ALL -ok | 表 ⽰全表扫描方怯,没用利用索引扫描类型; |
| 02 | index | 表 ⽰全索引扫描方怯,需要将索引树全部遍历,才能获取查询的信息(主键 index=全表扫描) |
| 03 | range | 表 ⽰范围索引方怯,按照索引的区域范围扫描数据,获取查询的数据信息; |
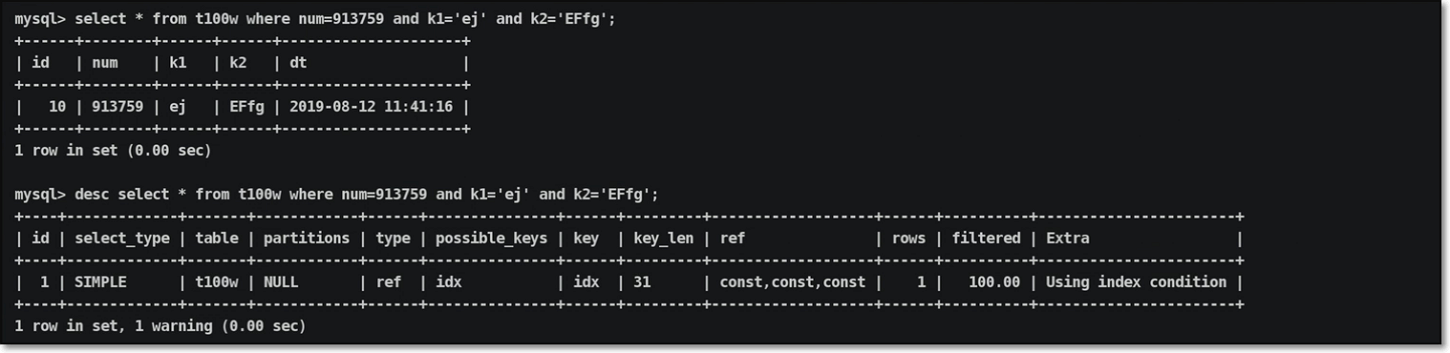
| 04 | ref | 表 ⽰辅助索引等值(常量)查询,精准定义辅助索引的查询条件 |
| 05 | eq_ ref | 表 ⽰多表连接查询时,被驱动表的连接条件是主键或者唯一键时,获取的数据信息过程; |
| 06 | const /system | 表 ⽰主键或者唯一键等值(常量)查询,精准定义索引的查询条件 |

此类型出现原因:查询条件不符合查询规律(like %%-只针对辅助索引,不影响主键索引-range);
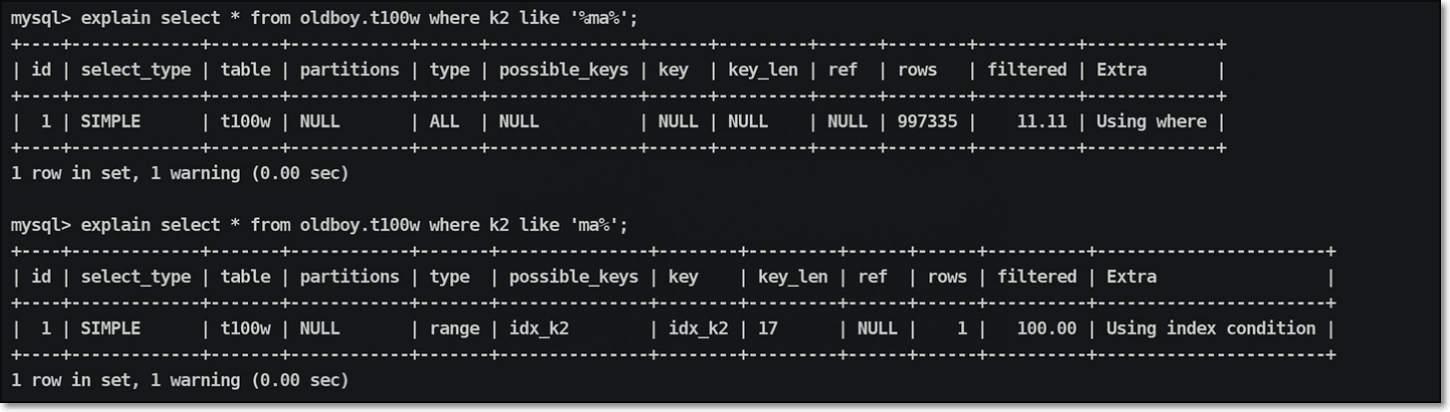
此类型出现原因:查询条件使用的了排除法(!=/not in-只针对辅助索引,不影响主键索引);

扫描类型-index:
此类型出现原因:扫描查询列设置了辅助索引信息,但是没有基于索引列设置查询条件

扫描类型-range:
此类型出现原因:查找条件是范围信息(> < >= <= between and in or)

特殊说明:在利用in查询数据信息时,查询效果和逻辑语句or的查询效果是一致;
此类型出现原因:查找条件是模糊信息(like)

扫描类型-ref:
此类型出现原因:查找条件是精确等值信息

扫描类型-eq_ref:
此类型出现原因:被驱动表的链表条件是主键或唯一键时
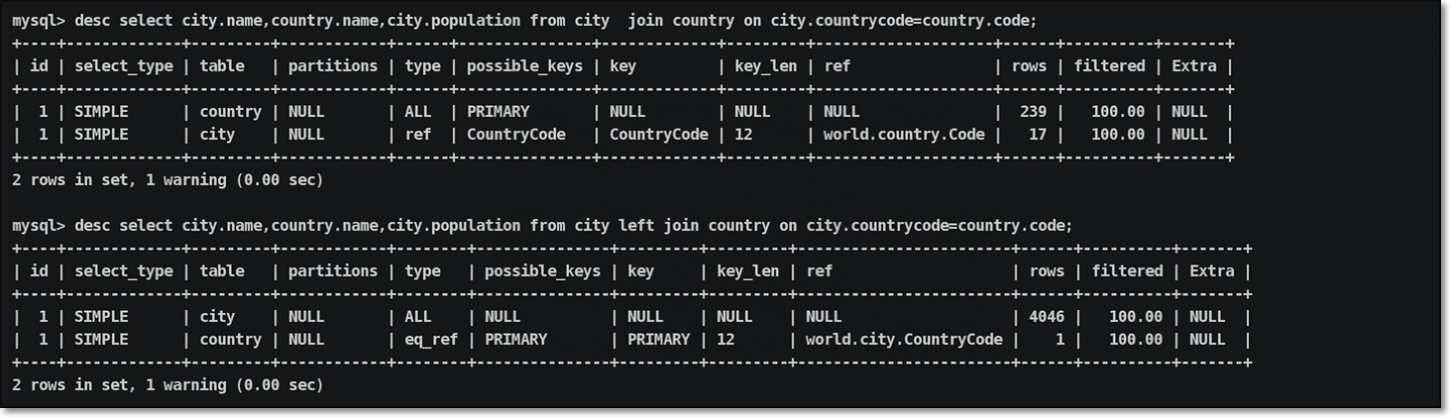
当连接查询没有where条件时:
左连接查询时,前面的表是驱动表,后面的表是被驱动表,右连接查询时相反;
内连接查询时,哪张表的数据较少,哪张表就是驱动表

当连接查询有where条件时,带where条件的表是驱动表,否则是被驱动表
说明:在没有设置比较合理索引情况下,默认选择结果集小的作为驱动表,即小表驱动大表;
但是,此时如果给city表中的population加上索引信息,查找数据的执行计划才是最优的,对应获取数据的性能是最好的;
MySQL驱动表和被驱动表说明:https://www.cnblogs.com/oldboy666/p/16892774.html
扫描类型-const:
此类型出现原因:查询的数据条件是主键或唯一键,并且是精确等值查询;

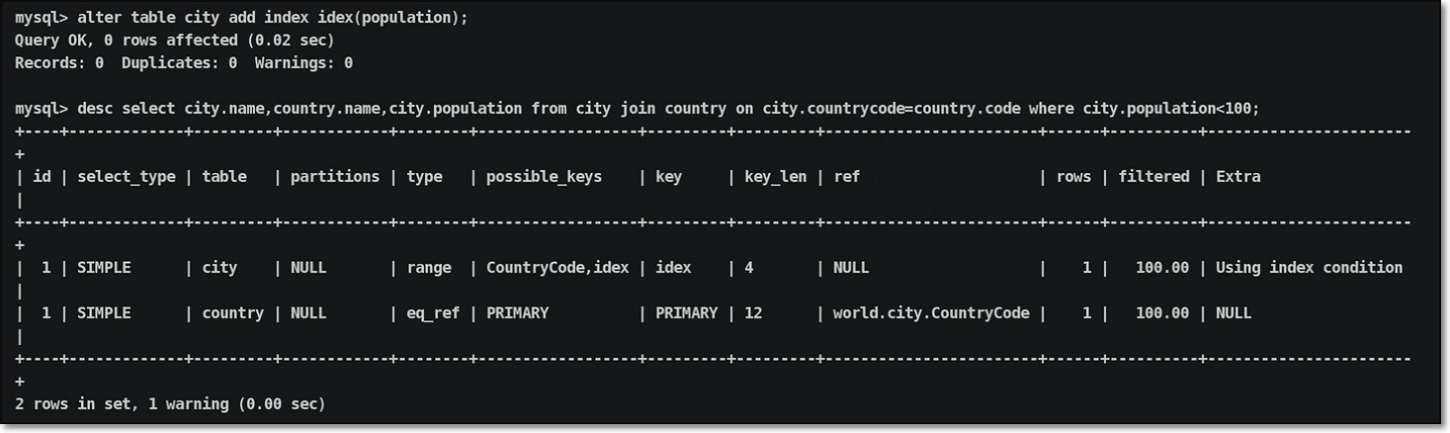
1.8.4 数据库索引覆盖长度
在执行计划列中,key_len主要用来判断联合索引覆盖长度(字节),当覆盖长度越长,就表示匹配度更高,回表查询的次数越少;
到底联合索引被覆盖了多少,是可以通过key_len计算出来;
| |
如果全部覆盖到了:长度=a+b+c 即三个列最大预留长度的总和
最大预留长度影响因素?
数据类型:
字符集(GBK:中文每个字符占用2个字节,英文1个字节 /UTF-8:中文每个字符占用3个字节,英文1个字节)
not null 是否可以为空 name
最大预留长度计算结果:不同的数据类型
| 字段 | 数据类型 | 字符集 | 计算结果 |
|---|---|---|---|
| name | char ( 10 ) | utf 8 mb 4 | 最大预留长度=4 * 10=40 10 |
| utf 8 | 最大预留长度=3 * 10=30 | ||
| varcher ( 10 ) | utf 8 mb 4 | 最大预留长度=4 * 10=40 + 2 字节=42 ( 1 - 2 字节存储字符长度信息 ) | |
| utf 8 | 最大预留长度=3 * 10=30 + 2 字节=32 ( 1 - 2 字节存储字符长度信息 ) | ||
| tinyint | N /A | 最大预留长度=1 (大约3位数) 2的8次方=256 | |
| int | N /A | 最大预留长度=4 (大约10位数) 2的32次方=4294967296 | |
| bigint | N /A | 最大预留长度=8 (大约 20 位数 ) 2 的 64 次方=18446744073709551616 | |
| not null | N /A | 在没有设置 not null 时,在以上情况计算结果再 + 1 |
| |
进行表结构信息与索引设置信息查询:
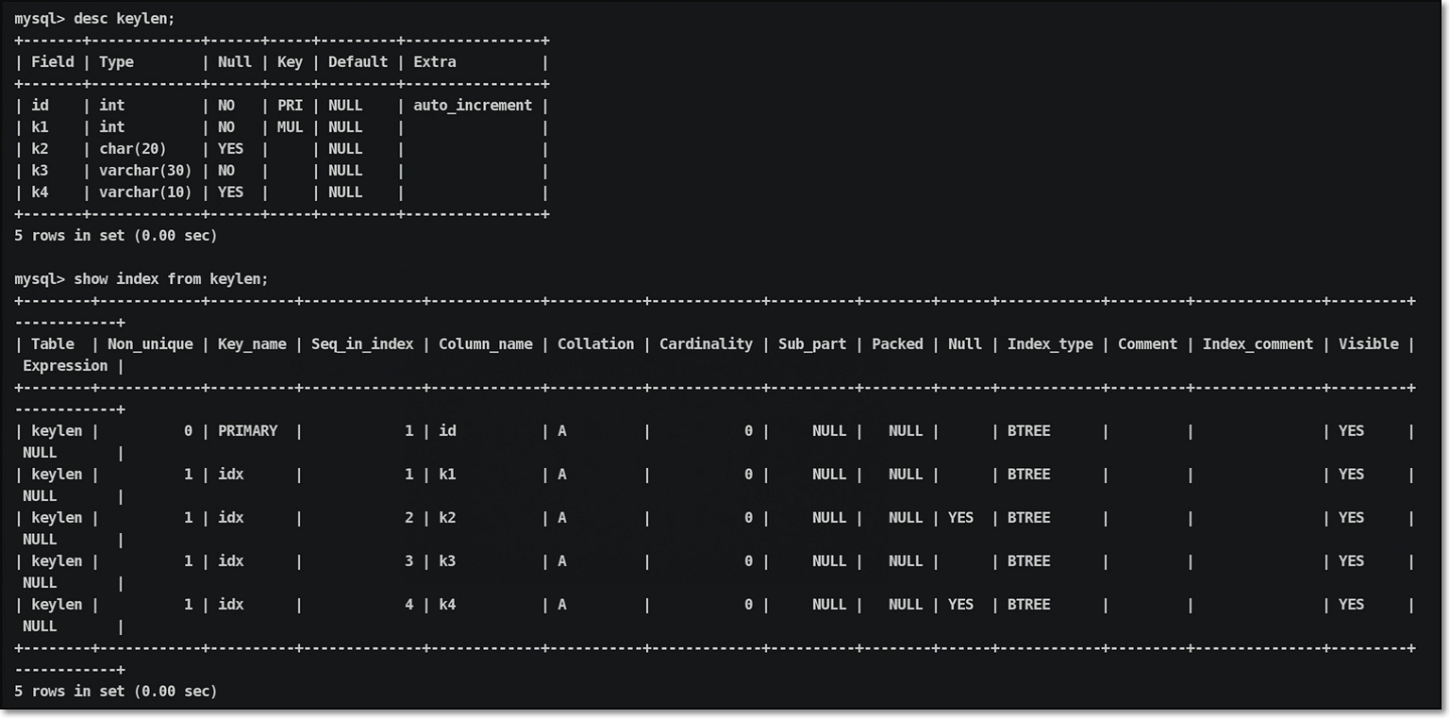
当四个索引信息全部覆盖,key_len数值计算结果:
| |

说明:根据key_len长度数值,理想上是和联合索引的最大预留长度越匹配越好,表示索引都用上了,回表次数自然会少;
1.8.5 数据库联合索引应用
联合索引可以优化表中多列信息的查询,当需要多列信息查询时最好应用联合索引,不要应用多个单列索引;
在进行联合索引应用设置时,也是需要满足一定规范要求的,即使建立的联合索引,可能某些情况下,联合索引也不能大部分被使用;
因此,建立了联合索引,肯定是希望联合索引走的越多越好,但也有可能联合索引建立存在问题,也会导致查询效率较低;
联合索引建立异常分析思路:创建好联合索引 + 合理应用联合索引发挥联合索引最大价值
联合索引建立没有问题,但是查询语句书写有问题,导致联合索引应用效果不好;
查询语句书写没有问题,但是联合索引建立有问题,导致数据查询结果性能过低;
联合索引应用要遵循最左原则:(以索引讲解表格进行说明最左原则)
建立索引的时候,最左列使用选择度高(cardinality-重复值少的列/唯一值多的列)的列
执行查询的时候,一定包含索引的最左条件;
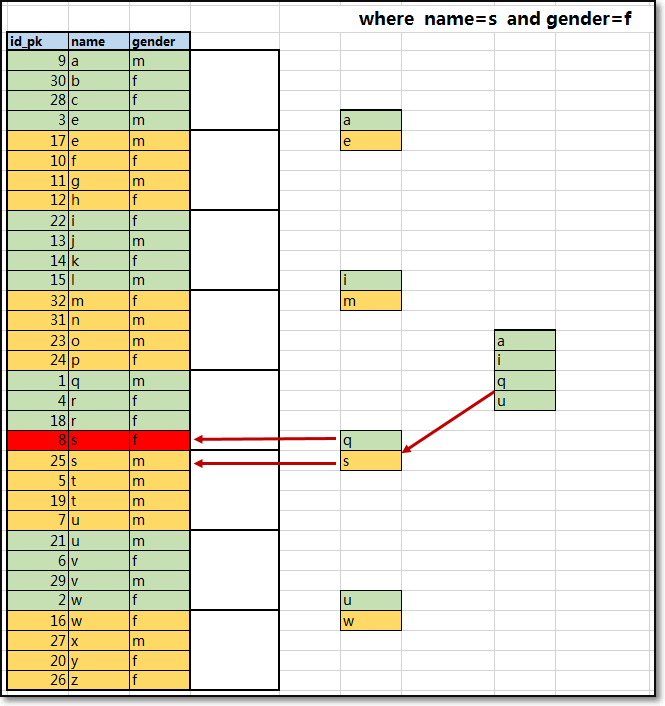
应用情况一:联合索引全部覆盖:
需要满足最左原则;(尽量)
需要定义条件信息时,将所有联合索引条件都引用;(必要)
进行实战测试环境练习,属于联合索引全覆盖情况:
实战测试01-步骤一:删除默认索引
| |
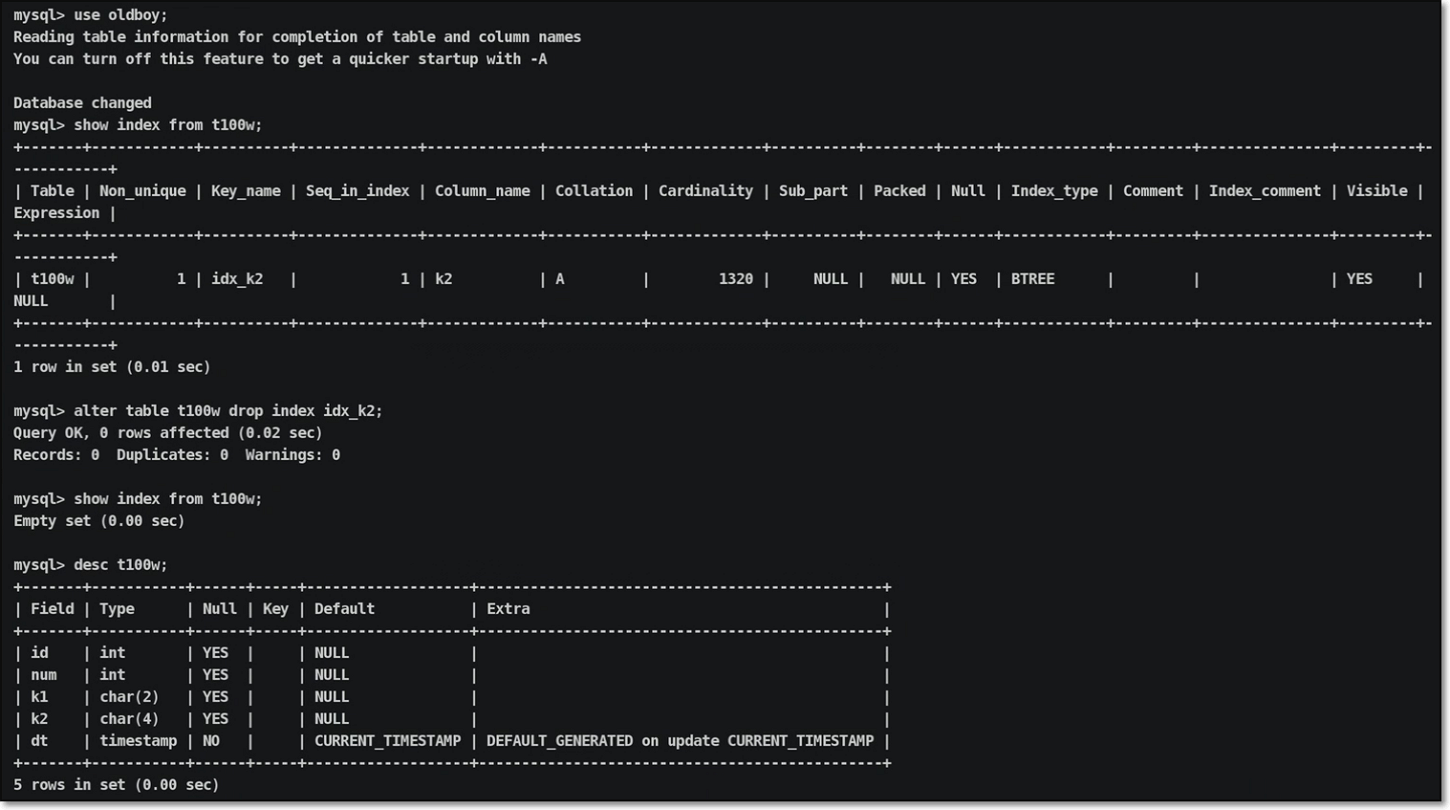
实战测试01-步骤二:创建测试环境
| |
联合索引创建情况:
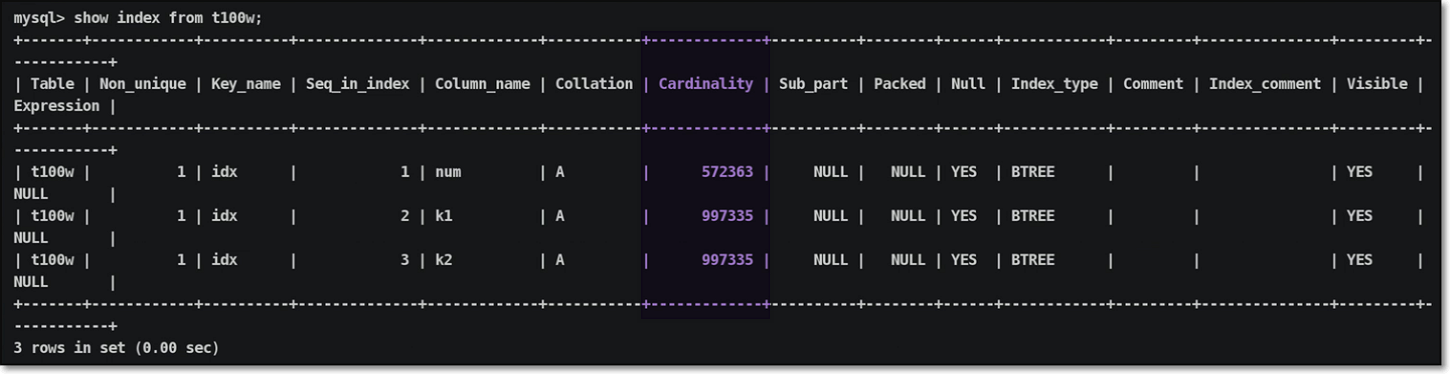
验证索引全覆盖最大预留长度
| |
最大预留长度验证结果:
说明:进行联合索引全覆盖时,索引条件的应用顺序是无关的,因为优化器会自动优化索引查询条件应用顺序;
实战测试02-步骤一:获取重复数据信息
| |
实战测试02-步骤二:插入新的测试数据
| |
实战测试02-步骤三:进行范围索引全覆盖查询
| |
查询的结果信息:
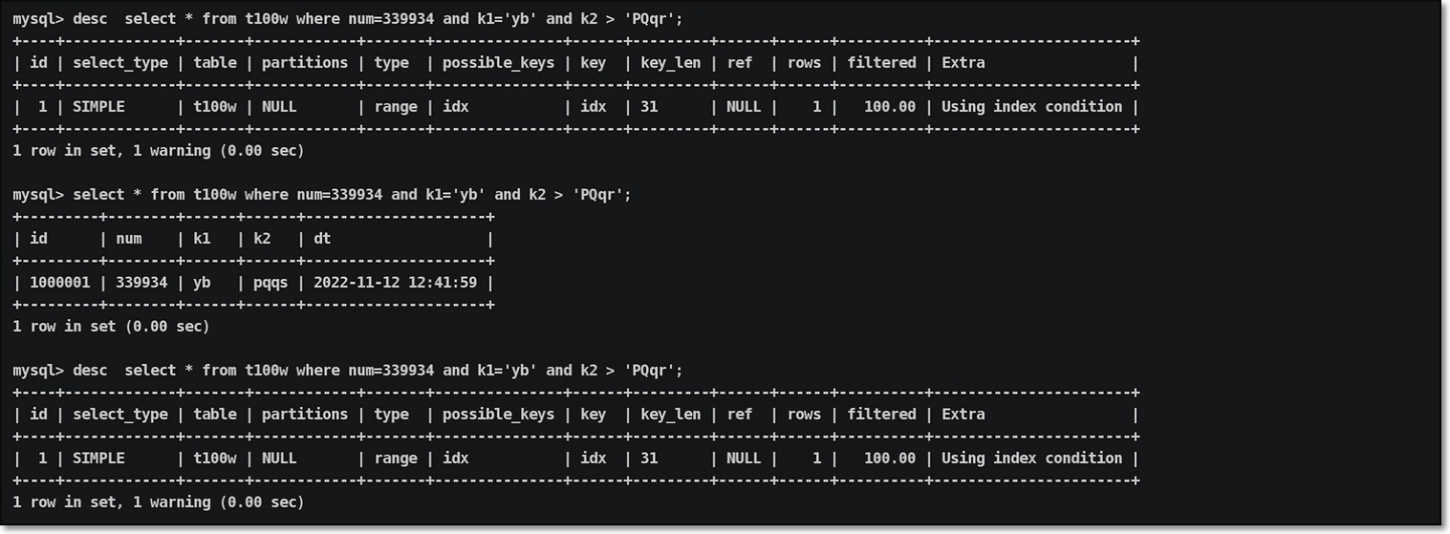
说明:在进行联合索引全覆盖查询时,最后一列不是精确匹配查询,而是采取区间范围查询,也可以实现索引全覆盖查询效果;
应用情况二:联合索引部分覆盖:
需要满足最左原则;
需要定义条件信息时,将所有联合索引条件部分引用;
进行实战测试环境练习,属性联合索引部分覆盖情况:
实战测试01-步骤一:进行部分查询测试
| |
查询的结果信息:

实战测试02-步骤一:临时关闭索引下推
| |
实战测试02-步骤二:进行部分列范围查询
| |
查询的结果信息:

说明:进行联合索引覆盖查询时,区间范围列不是最后一列,索引查询匹配只统计到区间范围匹配(不等值)列,也属于部分覆盖;
实战测试03-步骤一:进行部分查询测试
| |
查询的结果信息:

说明:进行联合索引覆盖查询时,查询索引列是不连续的,索引查询匹配只统计到缺失列前,也属于部分覆盖;
应用情况三:联合索引完全不覆盖:
需要定义条件信息时,将所有联合索引条件都不做引用;
进行实战测试环境练习,属性联合索引全不覆盖情况:
实战测试01-步骤一:进行索引查询测试
| |
实战测试02-步骤一:进行索引查询测试
| |
说明:进行联合索引全不覆盖查询时,区间范围列出现在了第一列,也属于全不覆盖索引
实战测试03-步骤一:进行索引查询测试
| |
说明:进行联合索引全不覆盖查询时,缺失最左列索引条件信息时,也属于全不覆盖索引
联合索引最左原则压力测试:
测试情况一:在不满足最左选择度高的情况;
| |
测试情况二:在满足最左选择度高的情况;
| |
1.8.6 数据库索引扩展信息
Extar列表示额外的情况或额外的信息说明,其中重点需要关注点信息为:filesort 表示涉及到额外排序操作,将严重浪费CPU资源;
哪些查询语句情况涉及到排序操作:
情况一:查询语句中含有 order by ,表示触发式的排序;
情况二:查询语句中含有 group by,表示隐藏式的排序;
情况三:查询语句中含有 DISTINCT,表示会先进行排序后再取消重复;
数据库查询出现排序情况演示说明:
进入到world数据库中,查看city索引信息设置,并将额外无用索引进行清理:
| |
索引信息清理后,索引状态情况:
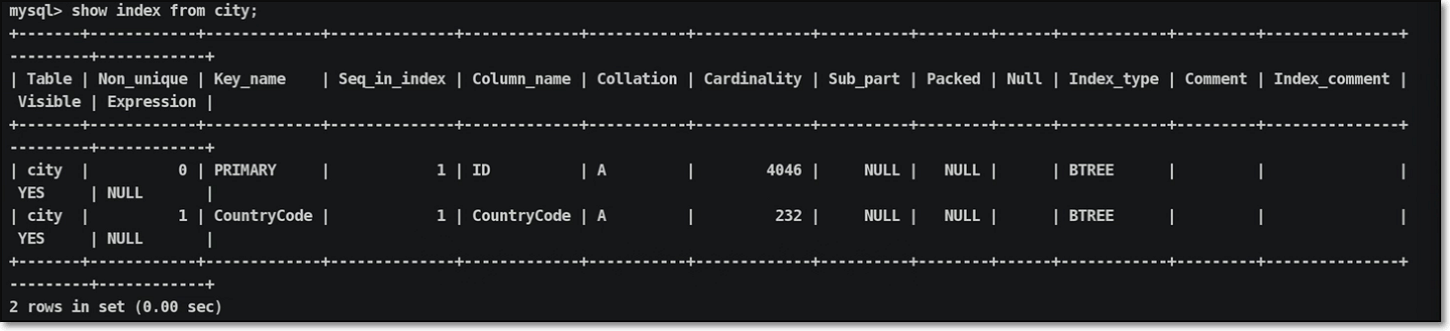
利用辅助索引信息作为条件,查看所有中国的城市情况信息:
| |
在没有进行排序前的执行计划情况:

模拟出现查询数据的排序情况:
| |
执行计划信息输出:

执行计划优化处理:
| |
实际效果信息输出:
没有改变最终的执行计划结果,因为在使用索引时,只能使用单一的索引树,不能跨越多颗索引树进行使用,因此优化失败;
| |
实际效果信息输出:

特殊情况说明:在order by信息出现在group by之后,是无法实现索引优化处理的
| |
实际效果信息输出:
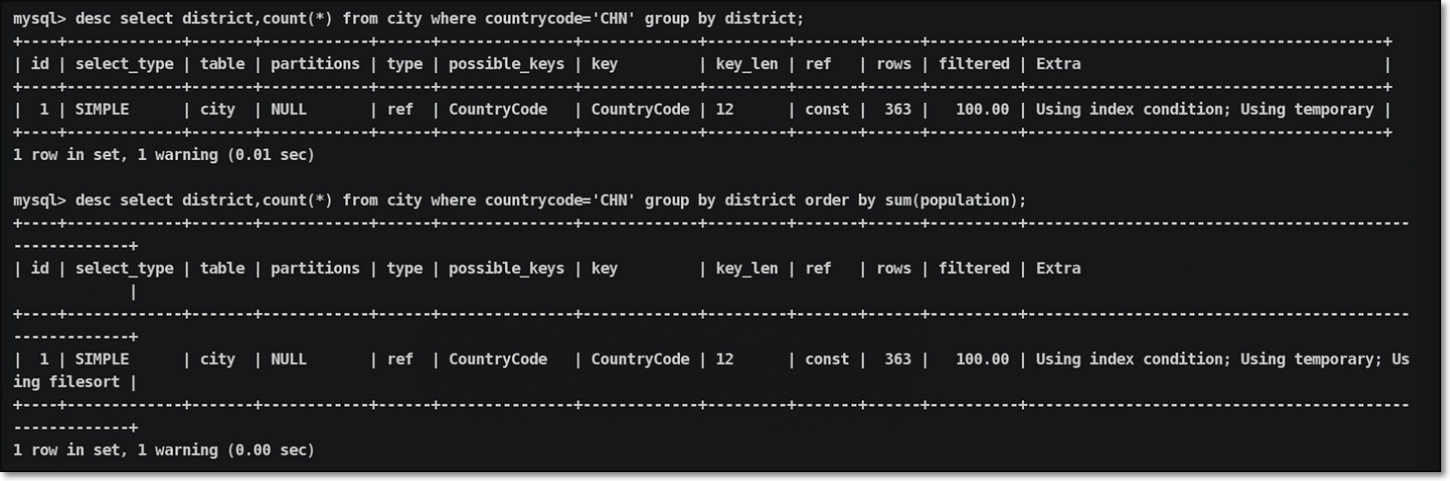
从上图执行计划输出信息可以看出,因为group by操作后,已经将数据信息存放在了临时表中,order by排序就不能再用索引了;
1.8.7 数据库索引应用总结
01 建立索引原则规范(DBA运维规范)
数据表中必须要有主键索引(创建表时指定),建议是与业务无关的自增列;
数据表中某些列若经常作为 where/order by/group by/join on/distinct条件信息,最好将相应列设置索引(产品功能/用户行为)
数据表中最好使用唯一值多的列作为索引,如果索引列重复值较多,可以考虑使用联合索引;(最左列-减少回表次数 - 减少磁盘IO)
数据表中列值长度较长的索引列,建议可以使用前缀索引;(防止索引树层次过高)
数据表中不建议建立大量索引,最好降低索引条目,不要创建无用索引,不常用的索引要定期清理(percona toolkit)
数据表中的索引信息做调整维护时,尽量避开业务繁忙期,或者通过软件工具做调整维护(pt-ost)
数据表中的联合索引创建过程要遵循索引最左原则;
02 索引应用失效情况(开发工作规范)
数据表信息查询时,没有设置查询条件信息;
数据表信息查询时,查询的条件没有建立索引;
| |
03 查询结果规范要求
当查询结果集数据是原表中的大部分数据,超过了总行数的25%,优化器便自动判断没必要走索引了,因为可以借助预读功能获取数据
可以通过精细查找指定数据的范围,从而达到优化的效果;(read_head预读相关参数)
04 索引失效情况处理
当频繁的对数据表中索引列值做修改、删除等操作时,会导致索引统计信息过旧或不真实,最终造成索引功能失效;
本身索引是有自我维护的机制能力,但并不是实时调整更新的,需要有一定的间隔时间做调整;
一般索引失效的表现情况为:select查询语句平常查询时很快,但突然某天执行就变慢了,就是索引失效了,统计数据不真实;
索引统计的信息存储位置:
| |
当索引失效时,可以使用命令重新进行统计信息获取,使索引功能再次生效:
| |
在查询条件过程中,使用了函数信息在索引列上,或者对索引进行了运算(+ - * / !等),都会导致索引功能失效,建议尽量避免;
| |
在查询数据信息过程中,出现了隐式转换也会导致索引失效;
| |
执行计划结果输出:
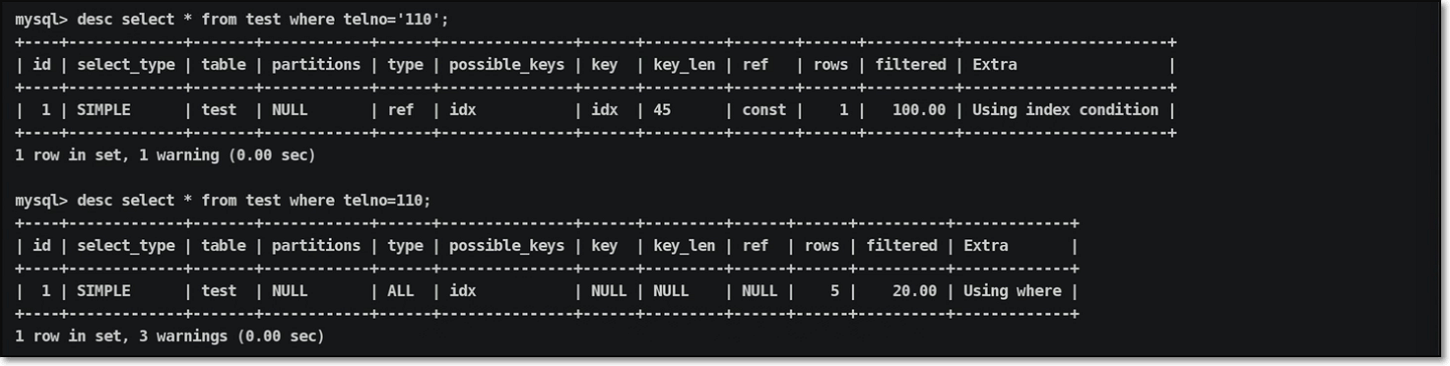
因为本身查询条件列的数据类型为字符类型,但是作为条件时当成了数字类型,数据库会将数值类型通过隐式转换函数转换为字符类型;
由于,条件中若加上了函数信息,就会导致索引功能失效,所以隐式转换也会造成索引失效;
在查询条件过程中,应用了特殊数据匹配方法时,也会导致索引失效,一般是辅助索引失效;
| |
1.8.8 数据库索引知识扩展
01 数据库服务索引功能特性
在新的数据库服务中,支持不可见索引功能
| |
执行计划信息输出:
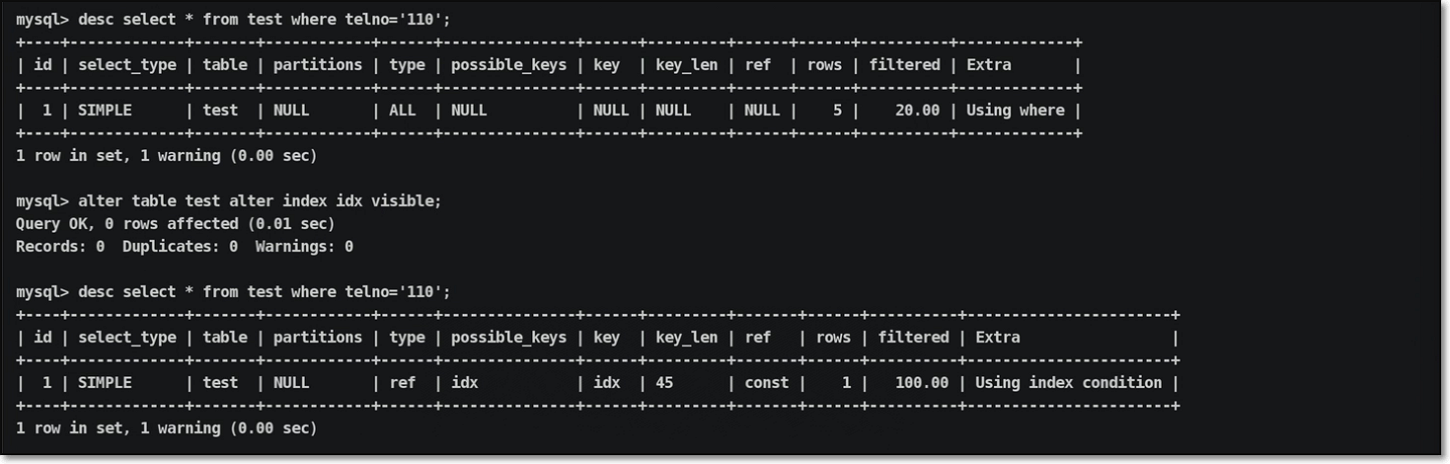
在新的数据库服务中,支持倒序索引功能
在早期数据库中,所有索引列创建索引信息,都是按照从小到大顺序进行排序,在最新数据库中,可以灵活调整索引排序方式;
| |
02 数据库服务自主优化能力
自主优化功能一:AHI(索引的索引)
AHI全称(中文名称)为自适应的hash索引/散列索引,用于在内存中建立索引,快速锁定内存中的热点数据索引页位置;
正常情况下,所有数据都是存储在磁盘中的,如果想访问读取相应磁盘的数据信息,都是会将磁盘数据调取存放在内存中,即消耗IO;
对于数据库服务而言,想要读取数据信息,也是会从磁盘中读取存储页,在放入内存中被数据库服务进行访问,索引访问也是一样的;
但是当数据页大量的被存放在内存中后,从大量内存中的数据页找到想要的,也是比较困难的事情;
因此,可以对内存中经常被访问数据索引页建立一个hash索引,从而可以帮助数据库服务快速定位内存中想要找的索引数据页;
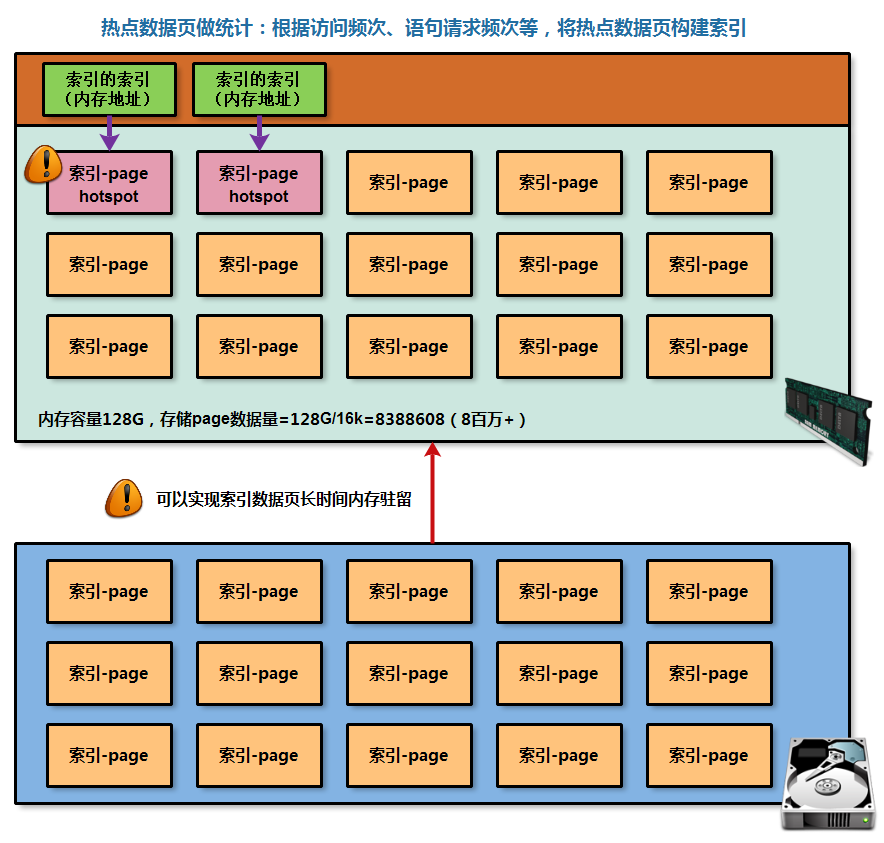
AHI功能配置信息:
| |
自主优化功能二:CHANGE BUFFER
早期版本称为 insert buffer,只是对插入操作有作用,版本更新后(5.6),可以对插入修改删除操作都有作用效果;
change buffer主要是针对辅助索引的缓冲区,属于内存结构上的应用;
changerbuffer应用原理:假设现在需要插入一行数据信息
① 插入一行数据信息到表中,将会实时立即更新聚簇索引信息,因为利用聚簇索引是用来获取数据页上详细原表数据信息的;
② 插入一行数据信息到表中,不会实时立即更新辅助索引信息,因为利用辅助索引是用来获取索引页上聚簇索引数据信息的;
如果此时实时更新了辅助索引的信息,有可能会导致出现数据页分裂,造成辅助索引树结构变化,形成索引树访问阻塞(锁机制);
③ 为了避免辅助索引树结构变更,对数据库服务并发访问的影响,可以将插入的数据信息,暂时存储在缓冲区中;
当利用辅助索引检索数据时,可以将检索到数据页范围信息调取到内存中,与缓存区数据进行合并,自然可以检索到插入的数据;
说明:在数据表中插入修改删除数据时,聚簇索引树会进行同步实时更新,辅助索引树会进行异步延时更新。
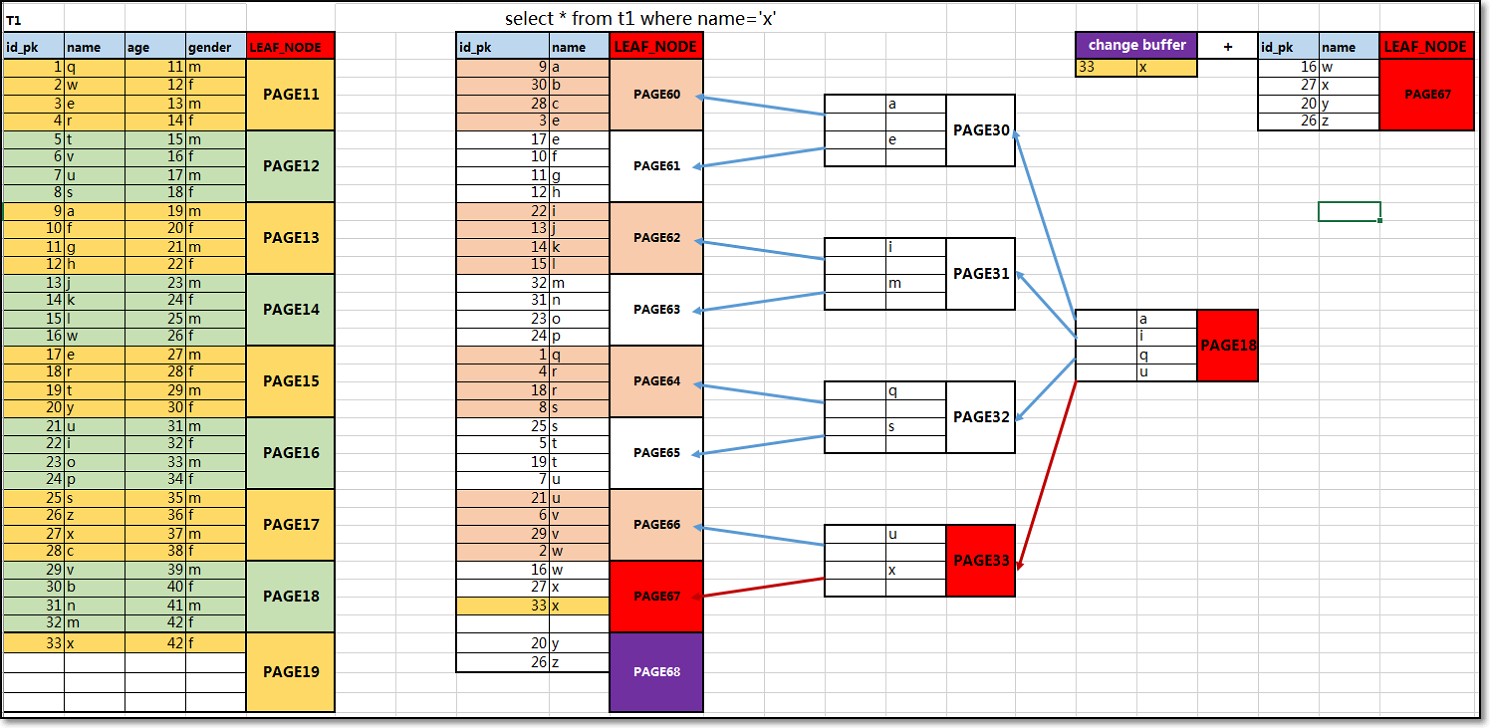
change_buffer功能配置信息:
| |
自主优化功能三:ICP (索引下推)
属于5.6之后引用的数据库服务新特性,称之为索引下推功能,主要是针对联合索引功能起作用;
ICP应用原理:假设创建联合索引进行数据检索
| |
在没有ICP优化机制情况:
基于联合索引的特性,查找检索数据只会依据a进行检索,可能检索到的数据页是100个数据块,会将数据放入内存中;
数据信息到达内存中后,在根据b和c的条件信息进行定位最终的聚簇索引信息,进行回表查询;
说明:基于数据库优化器的特性,遵循联合索引引用原则,SQL层面只能检索到联合索引中的A;
在应用ICP优化机制情况:
基于联合索引的特性,查找检索数据只会依据a进行检索,但是b和c也属于联合索引中的索引部分,在SQL层不能再进行索引情况下;
可以将b和c的检索工作下推交给引擎层完成,可以让引擎再调取数据到内存之前,再根据b和c的条件进行一次过滤;
可以将过滤后的数据信息再放入到内存中,然后结合获取到的聚簇索引信息,进行回表查询;
说明:基于数据库优化器的特性,可以将SQL层完成不了的检索工作,下推给引擎层完成,从而减少磁盘IO消耗,以及回表策略
ICP功能配置信息:
| |
自主优化功能四:MRR
MRR,全称(Multi-Range Read Optimization 多范围读取操作);
简单来说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
描述说明中涉及到的问题:
① 为什么要把随机读转换为顺序读?减少磁盘压力
② 为什么顺序读就能提升读取性能?
③ 如何将随机读去转换为顺序读取? MRR
MRR功能配置信息:
| |
